Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 114 results Python clear search
Fragile, Resilient, Asymmetric: An Agent-Based Stress Test of European Cooperation under Geopolitical Shocks (2024-2040)
Alessandro Brugnoletti | Published Thursday, July 16, 2026An empirically calibrated agent-based model of cooperation among 14 EU member states. Adaptive state-agents update their cooperation propensity through behavioural inertia, influence along the observed intra-EU trade network (IMF bilateral flows), and repeated-game payoff indicators built from verified Eurostat, Eurobarometer and IMF data (2021-2024). An anchored logistic mapping makes the observed configuration stationary in the absence of shocks, so outcomes read as deviations from the empirical baseline. The model stress-tests European cooperation to 2040 under five scenarios of increasing severity, from a baseline to a Taiwan Strait crisis counterfactual, with 1,000 Monte Carlo replications and a full sensitivity suite (one-factor-at-a-time, joint parameter sampling, breaking-point analysis, alternative functional form). Documented with the ODD protocol; self-testing and fully reproducible under fixed seeds.
An Agent-Based Model of Saving under Quasi-Hyperbolic Discounting on a Social Network.
Jose Alejandro Velazquez Monzon | Published Wednesday, June 24, 2026An agent-based model of saving and dissaving behaviour under quasi-hyperbolic (β–δ) discounting. Building on the individual decision problem of Cao and Werning (2018), the model embeds present-biased agents in a Watts–Strogatz small-world network and adds three configurable mechanisms of social influence — information diffusion, peer comparison, and social-norm conformity — across five heterogeneous behavioural profiles (Planners, Moderates, Procrastinators, Inverse Procrastinators, and Impulsive agents).
Each profile’s saving policy is approximated by value-function iteration over a discretised wealth grid; the solved policies are cached and applied as agents interact over their network neighbourhoods. The model tests whether each social mechanism can alter the saving and wealth trajectories that present-biased agents would otherwise follow in isolation, and characterises the direction and size of each effect on median wealth, wealth inequality (Gini), and the incidence of severely depleted agents.
The deposit includes the core model (Model.py), an analysis and visualisation pipeline (analyze_results.py), a standalone ODD description (ODD.md), and pinned dependencies.

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
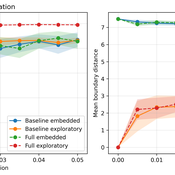
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…

PredPreyGrass
HBP1969 | Published Sunday, May 17, 2026Exploring learned cooperation, coevolution and free-riding. Learning is achieved through Multi-Agent Deep Reinforcement Learning (MADRL) in an ecological environment. The environment emits no other than sparse reproduction rewards. No reward shaping, no explicit cooperation signal.
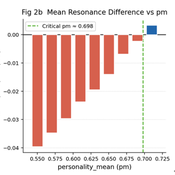
Zensei Wago: A Wealth-Integrated Social Capital Model
hiiki | Published Friday, May 15, 2026Interest-based compound economies generate monotonically increasing wealth inequality through multiplicative accumulation dynamics, yet the conditions under which gift-based reciprocal exchange outperforms such systems in collective well-being remain unquantified. We present Zensei Wago (全生和合), a seven-layer agent-based model comparing a Gift Resource Circulation (GRC) economy with a Compound Interest Circulation (CIC) economy under identical initial conditions. Across N = 5000 Monte Carlo replications (T = 700 ticks, N = 100 agents), GRC produced significantly higher collective resonance than CIC (p < 0.001, Cohen’s d = +0.171), above a critical prosocial threshold pm ≈ 0.698. Cohen’s d grows monotonically with duration — d = +1.943 at T = 1500 and d = +4.126 at T = 3000 — driven primarily by structural collapse of CIC resonance as inequality exceeds a critical Gini threshold (G > 0.333), while GRC resonance remains stable. The gift mechanism further decouples collective well-being from distributional outcomes, generating resonance through relational quality rather than material redistribution. Network topology analysis across seven configurations — combining a Watts-Strogatz rewiring sweep and a T = 1500 longitudinal replication — reveals that ring topology maximises GRC advantage (d = +1.17), that most topology-dependent reversals are transient (sparse and small-world both transition to significantly positive by T = 1500), and that a critical rewiring threshold of p ≈ 0.10–0.20 separates GRC-advantaged from GRC-disadvantaged network configurations. Scale-free networks remain persistently adverse (d = -7.24*), requiring structural redesign for gift-economy viability.
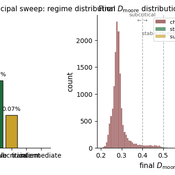
The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting
Eric Gladstone | Published Wednesday, May 13, 2026This computational model accompanies the article “The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting.” It implements an agent-based model in which agents infer latent neighborhood-type classes from noisy non-demographic cues through schema-specific diagnostic mappings, update beliefs, and relocate when satisfaction on a preferred latent class falls below a threshold.
The model serves as a mechanism-isolation device for studying the informational architecture underlying Schelling-style residential sorting. It includes the principal sweep configuration (14,400 runs across a seven-parameter grid), a disagreement-metric sub-sweep with permutation-minimized Jensen-Shannon divergence recorded natively, controls (positive, negative, and frozen-belief), a paired-seed cue-channel perturbation experiment, and selected-cell sensitivity sweeps for cue persistence and home-biased mobility.
The full ODD protocol, parameter manifests, deterministic seed schedules, processed outputs, regenerable figure scripts, the verification test suite, and the satisfaction-mapping audit document are included. Every reported run is deterministic given a (config, seed) pair, and an included audit script verifies bit-for-bit replay on sampled runs.
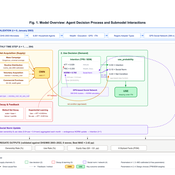
Peer reviewed Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026 | Last modified Tuesday, June 16, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.
Peer reviewed A dynamic identity model for misinformation in social networks
emdhar | Published Friday, February 27, 2026A dynamic identity model for misinformation in social networks, an agent-based model of social identity and misinformation dynamics.
I developed this model as a part of my master’s thesis, “Does social identity drive belief and persistence in online misinformation? An agent-based modelling approach” at University College Dublin, Ireland (2024-2025).
The purpose of this model is to further understand the dynamics of misinformation sharing as an expression of social identity. I introduce a framework to understand the influence of self-categorisation on misinformation persistence in social network. It integrates a social learning model with the Dynamic Identity Model for Agents (DIMA) using simple logic to simulate the social trade-offs driving misinformation and observe the effects on misinformation spread.
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Displaying 10 of 114 results Python clear search