Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1281 results
Leviathan model and its approximation
Thibaut Roubin Guillaume Deffuant | Published Thursday, September 17, 2020 | Last modified Monday, September 06, 2021The model is based on the influence function of the Leviathan model (Deffuant, Carletti, Huet 2013 and Huet and Deffuant 2017). We aim at better explaining some patterns generated by this model, using a derived mathematical approximation of the evolution of the opinions averaged.
We consider agents having an opinion/esteem about each other and about themselves. During dyadic meetings, agents change their respective opinion about each other, and possibly about other agents they gossip about, with a noisy perception of the opinions of their interlocutor. Highly valued agents are more influential in such encounters.
We show that the inequality of reputations among agents have a negative effect on the opinions about the agents of low status.The mathematical analysis of the opinion dynamic shows that the lower the status of the agent, the more detrimental the interactions are for the opinions about this agent, especially when gossip is activated, while the interactions always tend to increase the opinions about agents of high status.
Wolf-sheep predation Netlogo model, extended, with foresight
Guido Fioretti Andrea Policarpi | Published Wednesday, September 16, 2020 | Last modified Tuesday, April 13, 2021This model is an extension of the Netlogo Wolf-sheep predation model by U.Wilensky (1997). This extended model studies several different behavioural mechanisms that wolves and sheep could adopt in order to enhance their survivability, and their overall impact on global equilibrium of the system.

The uFUNK Model
Davide Secchi | Published Monday, August 31, 2020The agent-based simulation is set to work on information that is either (a) functional, (b) pseudo-functional, (c) dysfunctional, or (d) irrelevant. The idea is that a judgment on whether information falls into one of the four categories is based on the agent and its network. In other words, it is the agents who interprets a particular information as being (a), (b), (c), or (d). It is a decision based on an exchange with co-workers. This makes the judgment a socially-grounded cognitive exercise. The uFUNK 1.0.2 Model is set on an organization where agent-employee work on agent-tasks.
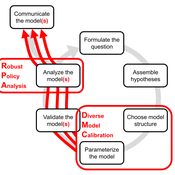
DMC-RPA: Diverse Model Calibration for Robust Policy Analysis (applied to an ABM of smallholder farmer resilience)
Tim Williams | Published Sunday, August 30, 2020This repository contains: (1) a model calibration procedure that identifies a set of diverse, plausible models; and (2) an ABM of smallholder agriculture, which is used as a case study application for the calibration method. By identifying a set of diverse models, the calibration method attends to the issue of “equifinality” prevalent in complex systems, which is a situation where multiple plausible process descriptions exist for a single outcome.
Mikania micrantha control in western Chitwan community forests
Jie Dai | Published Thursday, August 20, 2020This model simulates the household participation in large-scale M. micrantha intervention campaigns and the response of M. micrantha to the intervention.
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Gert Jan Hofstede Mark R Kramer Sebastian Fajardo Andrés Bernal Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.
Spread of COVID-19 in University Dormitory Setting
sunnyxjy | Published Sunday, August 16, 2020NetLogo agent-based model to simulate the transmission of COVID-19 in a university dormitory. User can set the number of initial students, buildings, floors, rooms, number of initially infected, and transmission rate. They can also test the effect of masks, sanitizations, elevator allowance, and visits on the effect of the SEIR curve.
Auctionsimulation
Deniz Kayar | Published Wednesday, August 12, 2020This repository the multi-agent simulation software for the paper “Comparison of Competing Market Mechanisms with Reinforcement Learning in a CarPooling Scenario”. It’s a mutlithreaded Javaapplication.
Can ethnic tolerance curb self-reinforcing school segregation? A theoretical Agent Based Model
Lucas Sage Andreas Flache | Published Monday, August 10, 2020Schelling and Sakoda prominently proposed computational models suggesting that strong ethnic residential segregation can be the unintended outcome of a self-reinforcing dynamic driven by choices of individuals with rather tolerant ethnic preferences. There are only few attempts to apply this view to school choice, another important arena in which ethnic segregation occurs. In the current paper, we explore with an agent-based theoretical model similar to those proposed for residential segregation, how ethnic tolerance among parents can affect the level of school segregation. More specifically, we ask whether and under which conditions school segregation could be reduced if more parents hold tolerant ethnic preferences. We move beyond earlier models of school segregation in three ways. First, we model individual school choices using a random utility discrete choice approach. Second, we vary the pattern of ethnic segregation in the residential context of school choices systematically, comparing residential maps in which segregation is unrelated to parents’ level of tolerance to residential maps reflecting their ethnic preferences. Third, we introduce heterogeneity in tolerance levels among parents belonging to the same group. Our simulation experiments suggest that ethnic school segregation can be a very robust phenomenon, occurring even when about half of the population prefers mixed to segregated schools. However, we also identify a “sweet spot” in the parameter space in which a larger proportion of tolerant parents makes the biggest difference. This is the case when parents have moderate preferences for nearby schools and there is only little residential segregation. Further experiments are presented that unravel the underlying mechanisms.
Venues and Segregation: A Revised Schelling Model
Ultan Byrne | Published Thursday, August 06, 2020This model examines an important but underappreciated mechanism affecting urban segregation and integration: urban venues. The venue- an area where urbanites interact- is an essential aspect of city life that tends to influence how satisfactory any location is. We study the venue/segregation relationship by installing venues into Schelling’s classic agent-based segregation model.
Displaying 10 of 1281 results