Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 11 results epstein clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Social Identity Model of Protest Emergence (SIMPE)
Cristina Chueca Del Cerro | Published Friday, March 17, 2023The Social Identity Model of Protest Emergence (SIMPE), an agent-based model of national identity and protest mobilisations.
I developed this model for my PhD project, “Polarisation and Protest Mobilisation Around Secessionist Movements: an Agent-Based Model of Online and Offline Social Networks”, at the University of Glasgow (2019-2023).
The purpose of this model is to simulate protest emergence in a given country where there is an independence movement, fostering the self-categorisation process of national identification. In order to contextualised SIMPE, I have used Catalonia, where an ongoing secessionist movement since 2011 has been present, national identity has shown signs of polarisation, and where numerous mobilisations have taken place over the last decade. Data from the Catalan Centre of Opinion Studies (CEO) has been used to inform some of the model parameters.
…
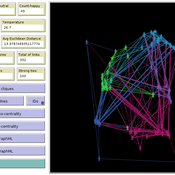
Cellular automata model of social networks
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.
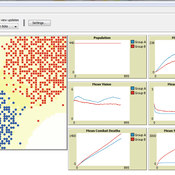
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
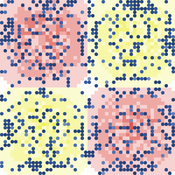
Sugarscape with spice
Marco Janssen | Published Tuesday, January 14, 2020 | Last modified Wednesday, June 24, 2026This is a variation of the Sugarspace model of Axtell and Epstein (1996) with spice and trade of sugar and spice. The model is not an exact replication since we have a somewhat simpler landscape of sugar and spice resources included, as well as a simple reproduction rule where agents with a certain accumulated wealth derive an offspring (if a nearby empty patch is available).
The model is discussed in Introduction to Agent-Based Modeling by Marco Janssen. For more information see https://intro2abm.com/

SugarscapeCW
Christopher Watts | Published Saturday, August 01, 2015 | Last modified Wednesday, April 12, 2023A replication in Netlogo 5.2 of the classic model, Sugarscape (Epstein & Axtell, 1996).

Thoughtless conformity and spread of norms in an artificial society (Grid Model)
Muhammad Azfar Nisar | Published Tuesday, May 27, 2014This model is a small extension (rectangular layout) of Joshua Epstein’s (2001) model on development of thoughtless conformity in an artificial society of agents.
Thoughtless conformity and spread of norms in an artificial society
Muhammad Azfar Nisar | Published Tuesday, May 27, 2014This model is based on Joshua Epstein’s (2001) model on development of thoughtless conformity in an artificial society of agents.
Displaying 10 of 11 results epstein clear search