Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 109 results for "Kristen Ross" clear search
Social norms and the dominance of Low-doers
Antonio Franco | Published Wednesday, July 13, 2016 | Last modified Sunday, December 02, 2018The code for the paper “Social norms and the dominance of Low-doers”
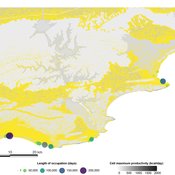
PaleoscapeABM: coastal occupation and shellfish discard
Claudine Gravel-Miguel | Published Tuesday, February 08, 2022This model builds on the Armature distribution within the PaleoscapeABM model, which is itself a variant of the PaleoscapeABM available here written by Wren and Janssen, and.
This model aims to explore where and how much shellfish is discarded at coastal and non-coastal locations by daily coastal foraging. We use this model’s output to test the idea that we can confidently use the archaeological record to evaluate the importance of shellfish in prehistoric people’s diets.
The recognition that aquatic adaptations likely had significant impacts on human evolution triggered an explosion of research on that topic. Recognizing coastal foraging in the past relies on the archaeological signature of that behavior. We use this model to explore why some coastal sites are very intensely occupied and see if it is due to the shellfish productivity of the coast.

Soil microbe-predator model with enzymes
Randall Boone John C Moore Akihiro Koyama Kirstin Holfelder | Published Thursday, November 21, 2013We seek to improve understanding of roles enzyme play in soil food webs. We created an agent-based simulation of a simple food web that includes enzymatic activity. The model was used in a publication, Moore et al. (in press; Biochemistry).
SimPioN - Simulating Path dependence in inter-organisational Networks
Nanda Wijermans Frithjof Stöppler | Published Monday, January 11, 2021The SimPioN model aims to abstractly reproduce and experiment with the conditions under which a path-dependent process may lead to a (structural) network lock-in in interorganisational networks.
Path dependence theory is constructed around a process argumentation regarding three main elements: a situation of (at least) initially non-ergodic (unpredictable with regard to outcome) starting conditions in a social setting; these become reinforced by the workings of (at least) one positive feedback mechanism that increasingly reduces the scope of conceivable alternative choices; and that process finally results in a situation of lock-in, where any alternatives outside the already adopted options become essentially impossible or too costly to pursue despite (ostensibly) better options theoretically being available.
The purpose of SimPioN is to advance our understanding of lock-ins arising in interorganisational networks based on the network dynamics involving the mechanism of social capital. This mechanism and the lock-ins it may drive have been shown above to produce problematic consequences for firms in terms of a loss of organisational autonomy and strategic flexibility, especially in high-tech knowledge-intensive industries that rely heavily on network organising.
…
A Simple Agent Based Modeling Tool for Plastic and Debris Tracking in Oceans
Subu Kandaswamy Koushik Sura Bhaskar Sai Amulya Murukutla Sai Pranay Raju Chinthala Abhishek Bobbillapati | Published Monday, October 04, 2021Plastics and the pollution caused by their waste have always been a menace to both nature and humans. With the continual increase in plastic waste, the contamination due to plastic has stretched to the oceans. Many plastics are being drained into the oceans and rose to accumulate in the oceans. These plastics have seemed to form large patches of debris that keep floating in the oceans over the years. Identification of the plastic debris in the ocean is challenging and it is essential to clean plastic debris from the ocean. We propose a simple tool built using the agent-based modeling framework NetLogo. The tool uses ocean currents data and plastic data both being loaded using GIS (Geographic Information System) to simulate and visualize the movement of floatable plastic and debris in the oceans. The tool can be used to identify the plastic debris that has been piled up in the oceans. The tool can also be used as a teaching aid in classrooms to bring awareness about the impact of plastic pollution. This tool could additionally assist people to realize how a small plastic chunk discarded can end up as large debris drifting in the oceans. The same tool might help us narrow down the search area while looking out for missing cargo and wreckage parts of ships or flights. Though the tool does not pinpoint the location, it might help in reducing the search area and might be a rudimentary alternative for more computationally expensive models.
HomininSpace
Fulco Scherjon | Published Friday, November 25, 2016 | Last modified Tuesday, October 06, 2020A modelling system to simulate Neanderthal demography and distribution in a reconstructed Western Europe for the late Middle Paleolithic.
CINCH1 (Covid-19 INfection Control in Hospitals)
Nick Gotts | Published Sunday, August 29, 2021CINCH1 (Covid-19 INfection Control in Hospitals), is a prototype model of physical distancing for infection control among staff in University College London Hospital during the Covid-19 pandemic, developed at the University of Leeds, School of Geography. It models the movement of collections of agents in simple spaces under conflicting motivations of reaching their destination, maintaining physical distance from each other, and walking together with a companion. The model incorporates aspects of the Capability, Opportunity and Motivation of Behaviour (COM-B) Behaviour Change Framework developed at University College London Centre for Behaviour Change, and is aimed at informing decisions about behavioural interventions in hospital and other workplace settings during this and possible future outbreaks of highly contagious diseases. CINCH1 was developed as part of the SAFER (SARS-CoV-2 Acquisition in Frontline Health Care Workers – Evaluation to Inform Response) project
(https://www.ucl.ac.uk/behaviour-change/research/safer-sars-cov-2-acquisition-frontline-health-care-workers-evaluation-inform-response), funded by the UK Medical Research Council. It is written in Python 3.8, and built upon Mesa version 0.8.7 (copyright 2020 Project Mesa Team).

Simulating the cost of social care in an ageing population
Eric Silverman | Published Thursday, September 16, 2021This model is an agent-based simulation written in Python 2.7, which simulates the cost of social care in an ageing UK population. The simulation incorporates processes of population change which affect the demand for and supply of social care, including health status, partnership formation, fertility and mortality. Fertility and mortality rates are drawn from UK population data, then projected forward to 2050 using the methods developed by Lee and Carter 1992.
The model demonstrates that rising life expectancy combined with lower birthrates leads to growing social care costs across the population. More surprisingly, the model shows that the oft-proposed intervention of raising the retirement age has limited utility; some reductions in costs are attained initially, but these reductions taper off beyond age 70. Subsequent work has enhanced and extended this model by adding more detail to agent behaviours and familial relationships.
The version of the model provided here produces outputs in a format compatible with the GEM-SA uncertainty quantification software by Kennedy and O’Hagan. This allows sensitivity analyses to be performed using Gaussian Process Emulation.
Digital divide and opinion formation
Dongwon Lim | Published Friday, November 02, 2012 | Last modified Monday, May 20, 2013This model extends the bounded confidence model of Deffuant and Weisbuch. It introduces online contexts in which a person can deliver his or her opinion to several other persons. There are 2 additional parameters accessibility and connectivity.
Peer reviewed Historical Letters
Bernardo Buarque Malte Vogl Jascha Merijn Schmitz Aleksandra Kaye | Published Thursday, May 16, 2024 | Last modified Friday, May 24, 2024A letter sending model with historically informed initial positions to reconstruct communication and archiving processes in the Republic of Letters, the 15th to 17th century form of scholarship.
The model is aimed at historians, willing to formalize historical assumptions about the letter sending process itself and allows in principle to set heterogeneous social roles, e.g. to evaluate the role of gender or social status in the formation of letter exchange networks. The model furthermore includes a pruning process to simulate the loss of letters to critically asses the role of biases e.g. in relation to gender, geographical regions, or power structures, in the creation of empirical letter archives.
Each agent has an initial random topic vector, expressed as a RGB value. The initial positions of the agents are based on a weighted random draw based on data from [2]. In each step, agents generate two neighbourhoods for sending letters and potential targets to move towards. The probability to send letters is a self-reinforcing process. After each sending the internal topic of the receiver is updated as a movement in abstract space by a random amount towards the letters topic.
…
Displaying 10 of 109 results for "Kristen Ross" clear search