Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1221 results for "Ian M Hamilton" clear search
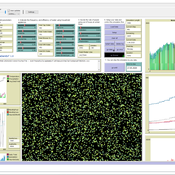
Peer reviewed WaDemEsT-Water Demand Estimation Tool for Residential Areas
Kamil Aybuğa | Published Tuesday, February 18, 2025This model simulates household water consumption patterns in an urban environment. Its current setup compares monthly water consumption data, and the results of a daily heuristic water demand model with the simulation results produced by household demographics that is fine tuned via some base demand model. It’s designed to estimate and analyze water demand based on various factors including household demographics, daily routines of residents (working, weekending, vacation patterns), weather conditions (temperature and precipitation), appliance usage patterns, seasonal variations, and special periods such as weekends and holidays. The model aims to help understand how different factors influence residential water consumption and can be used for water demand forecasting and management.
NarrABS
Tilman Schenk | Published Thursday, September 20, 2012 | Last modified Saturday, April 27, 2013An agent based simulation of a political process based on stakeholder narratives
Social model of a Team Developing a Planning-Methodology
Oswaldo Terán Christophe Sibertin | Published Monday, November 18, 2013 | Last modified Sunday, November 16, 2014The model represents a team intended at designing a methodology for Institutional Planning. Included in ICAART’14 to exemplify how emotions can be identified in SocLab; and in ESSA’14 to show the Efficiency of Organizational Withdrawal vs Commitment.

AnimDens NetLogo
Miguel Pais Christine Ward-Paige | Published Friday, February 10, 2017 | Last modified Sunday, February 23, 2020The model demonstrates how non-instantaneous sampling techniques produce bias by overestimating the number of counted animals, when they move relative to the person counting them.
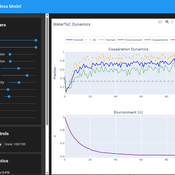
Tragedy of the Commons with Environmental Feedback: A Model of Human-AI Socio-Environmental Water Dilemma
Ivana Malcic Luka Waronig Andrew Crossley | Published Saturday, July 05, 2025 | Last modified Sunday, July 06, 2025This project is an interactive agent-based model simulating consumption of a shared, renewable resource using a game-theoretic framework with environmental feedback. The primary function of this model was to test how resource-use among AI and human agents degrades the environment, and to explore the socio-environmental feedback loops that lead to complex emergent system dynamics. We implemented a classic game theoretic matrix which decides agents´ strategies, and added a feedback loop which switches between strategies in pristine vs degraded environments. This leads to cooperation in bad environments, and defection in good ones.
Despite this use, it can be applicable for a variety of other scenarios including simulating climate disasters, environmental sensitivity to resource consumption, or influence of environmental degradation to agent behaviour.
The ABM was inspired by the Weitz et. al. (2016, https://pubmed.ncbi.nlm.nih.gov/27830651/) use of environmental feedback in their paper, as well as the Demographic Prisoner’s Dilemma on a Grid model (https://mesa.readthedocs.io/stable/examples/advanced/pd_grid.html#demographic-prisoner-s-dilemma-on-a-grid). The main innovation is the added environmental feedback with local resource replenishment.
Beyond its theoretical insights into coevolutionary dynamics, it serves as a versatile tool with several practical applications. For urban planners and policymakers, the model can function as a ”digital sandbox” for testing the impacts of locating high-consumption industrial agents, such as data centers, in proximity to residential communities. It allows for the exploration of different urban densities, and the evaluation of policy interventions—such as taxes on defection or subsidies for cooperation—by directly modifying the agents’ resource consumptions to observe effects on resource health. Furthermore, the model provides a framework for assessing the resilience of such socio-environmental systems to external shocks.
…
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Growing Unpopular Norms. A Network-Situated ABM of Norm Choice.
C Merdes | Published Tuesday, November 22, 2016 | Last modified Saturday, March 17, 2018The model’s purpose is to provide a potential explanation for the emergence, sustenance and decline of unpopular norms based on pluralistic ignorance on a social network.
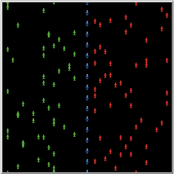
The Thin Blue Line Between Protesters and Their Counter-Protesters
Tamsin Lee | Published Monday, March 26, 2018More frequently protests are accompanied by an opposing group performing a counter protest. This phenomenon can increase tension such that police must try to keep the two groups separated. However, what is the best strategy for police? This paper uses a simple agent-based model to determine the best strategy for keeping the two groups separated. The ‘thin blue line’ varies in density (number of police), width and the keenness of police to approach protesters. Three different groups of protesters are modelled to mimic peaceful, average and volatile protests. In most cases, a few police forming a single-file ‘thin blue line’ separating the groups is very effective. However, when the protests are more volatile, it is more effective to have many police occupying a wide ‘thin blue line’, and police being keen to approach protesters. To the authors knowledge, this is the first paper to model protests and counter-protests.
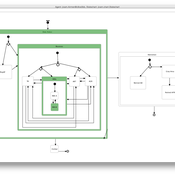
Life Cycle Cost of Military Manpower Model
Jonathan Ozik Todd Combs | Published Monday, January 05, 2015We demonstrate how Repast Simphony statecharts can efficiently encapsulate the deep classification hierarchy of the U.S. Air Force for manpower life cycle costing.
This is a social trust model for investigating the social relationships and social networks in the real world and in social media.
Displaying 10 of 1221 results for "Ian M Hamilton" clear search