Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 94 results for "Guillermo P Podestá" clear search
Peer reviewed Personnel decisions in the hierarchy
Smarzhevskiy Ivan | Published Friday, August 19, 2022This is a model of organizational behavior in the hierarchy in which personnel decisions are made.
The idea of the model is that the hierarchy, busy with operations, is described by such characteristics as structure (number and interrelation of positions) and material, filling these positions (persons with their individual performance). A particular hierarchy is under certain external pressure (performance level requirement) and is characterized by the internal state of the material (the distribution of the perceptions of others over the ensemble of persons).
The World of the model is a four-level hierarchical structure, consisting of shuff positions of the top manager (zero level of the hierarchy), first-level managers who are subordinate to the top manager, second-level managers (subordinate to the first-level managers) and positions of employees (the third level of the hierarchy). ) subordinated to the second-level managers. Such a hierarchy is a tree, i.e. each position, with the exception of the position of top manager, has a single boss.
Agents in the model are persons occupying the specified positions, the number of persons is set by the slider (HumansQty). Personas have some operational performance (harisma, an unfortunate attribute name left over from the first edition of the model)) and a sense of other personas’ own perceptions. Performance values are distributed over the ensemble of persons according to the normal law with some mean value and variance.
The value of perception by agents of each other is positive or negative (implemented in the model as numerical values equal to +1 and -1). The distribution of perceptions over an ensemble of persons is implemented as a random variable specified by the probability of negative perception, the value of which is set by the control elements of the model interface. The numerical value of the probability equal to 0 corresponds to the case in which all persons positively perceive each other (the numerical value of the random variable is equal to 1, which corresponds to the positive perception of the other person by the individual).
The hierarchy is occupied with operational activity, the degree of intensity of which is set by the external parameter Difficulty. The level of productivity of each manager OAIndex is equal to the level of productivity of the department he leads and is the ratio of the sum of productivity of employees subordinate to the head to the level of complexity of the work Difficulty. An increase in the numerical value of Difficulty leads to a decrease in the OAIndex for all subdivisions of the hierarchy. The managerial meaning of the OAIndex indicator is the percentage of completion of the load specified for the hierarchy as a whole, i.e. the ratio of the actual performance of the structural subdivisions of the hierarchy to the required performance, the level of which is specified by the value of the Difficulty parameter.
…
Agent-based model of power dynamics in agri-food systems
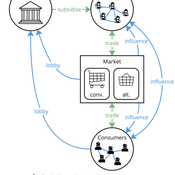
Tim Williams | Published Sunday, October 27, 2024 | Last modified Thursday, June 12, 2025This is a stylised agent-based model designed to explore the conditions that lead to lock-ins and transitions in agri-food systems.
The model represents interactions between four different types of agents: farmers, consumers, markets, and the state. Farmers and consumers are heterogeneous, and at each time step decide whether to trade with one of two market agents: the conventional or alternative. The state agent provides subsidies to the farmers at each time step.
The key emergent outcome is the fraction of trade in each time step that flows through the alternative market agent. This arises from the distributed decisions of farmer and consumer agents. A “sustainability transition” is defined as a shift in the dominant practices (and associated balance of power) towards the alternative paradigm.
…
Peer reviewed AMRO_CULEX_WNV
Aniruddha Belsare Jennifer Owen | Published Saturday, February 27, 2021 | Last modified Thursday, March 11, 2021An agent-based model simulating West Nile Virus dynamics in a one host (American robin)-one vector (Culex spp. mosquito) system. ODD improved and code cleaned.
Socio-hydrologicalModel_version_SESMO
Marco Janssen Andres Baeza-Castro Paola Gomez Luis Bojorquez Fidel Serrano-Candela Hallie Eakin Yosune Miquelajauregui Rodrigo Garcia-Herrera | Published Tuesday, February 05, 2019We present here MEGADAPT_SESMO model. A hybrid, dynamic, spatially explicit, integrated model to simulate the vulnerability of urban coupled socio-ecological systems – in our case, the vulnerability of Mexico City to socio-hydrological risk.
Success bias imitation increases the probability of effectively dealing with ecological disturbances
Jacopo A. Baggio Vicken Hillis | Published Thursday, April 13, 2017 | Last modified Thursday, August 02, 2018This model aims to investigate how different type of learning (social system) and disturbance specific attributes (ecological system) influence adoption of treatment strategies to treat the effects of ecological disturbances.
Agent modeling (ABM) as a tool to improve the mobility of “avoidant” birds in an ecological corridor in the localities of Chapinero, Teusaquillo, Barrios Unidos and Engativá of Bogotá city [Scenario 2]
Paula Alejandra Meza | Published Thursday, June 25, 2026Considering that two of the three avoider species could not reach the target area in the inittial scenario, five alternative corridor scenarios were created. In all cases, we generated a greater amount of cover area under ‘Urban forest’, including elements such as scattered trees, woody plants, wooded areas, and rows of trees. This covered type was selected since all three species use it as a regular habitat. That is the second sceneario where those ecological parks and other areas inside the capital city were boostered into “urban forest patches” or buffer points, with the idea of improving the survive of the three bird species and their movement. However one of the most restrictive specie was still having movement and survival issues.
Individual bias and organizational objectivity
Bo Xu | Published Monday, April 15, 2013 | Last modified Monday, April 08, 2019This model introduces individual bias to the model of exploration and exploitation, simulates knowledge diffusion within organizations, aiming to investigate the effect of individual bias and other related factors on organizational objectivity.

REHAB: A Role Playing Game to Explore the Influence of Knowledge and Communication on Natural Resources Management
Christophe Le Page Anne Dray Pascal Perez Claude Garcia | Published Monday, July 13, 2015 | Last modified Monday, July 13, 2015REHAB has been designed as an ice-breaker in courses dealing with ecosystem management and participatory modelling. It helps introducing the two main tools used by the Companion Modelling approach, namely role-playing games and agent-based models.
MayaSim: An agent-based model of the ancient Maya social-ecological system
Scott Heckbert | Published Wednesday, July 11, 2012 | Last modified Tuesday, July 02, 2013MayaSim is an agent-based, cellular automata and network model of the ancient Maya. Biophysical and anthropogenic processes interact to grow a complex social ecological system.
Human-in-the-loop Experiment of the Strategic Coalition Formation using the glove game
Andrew Collins | Published Monday, November 23, 2020 | Last modified Wednesday, June 22, 2022The purpose of the model is to collect information on human decision-making in the context of coalition formation games. The model uses a human-in-the-loop approach, and a single human is involved in each trial. All other agents are controlled by the ABMSCORE algorithm (Vernon-Bido and Collins 2020), which is an extension of the algorithm created by Collins and Frydenlund (2018). The glove game, a standard cooperative game, is used as the model scenario.
The intent of the game is to collection information on the human players behavior and how that compares to the computerized agents behavior. The final coalition structure of the game is compared to an ideal output (the core of the games).
Displaying 10 of 94 results for "Guillermo P Podestá" clear search