Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 972 results for "Ibo van de Poel" clear search

Peer reviewed The Megafauna Hunting Pressure Model
Isaac Ullah Miriam C. Kopels | Published Friday, February 16, 2024 | Last modified Friday, October 11, 2024The Megafaunal Hunting Pressure Model (MHPM) is an interactive, agent-based model designed to conduct experiments to test megaherbivore extinction hypotheses. The MHPM is a model of large-bodied ungulate population dynamics with human predation in a simplified, but dynamic grassland environment. The overall purpose of the model is to understand how environmental dynamics and human predation preferences interact with ungulate life history characteristics to affect ungulate population dynamics over time. The model considers patterns in environmental change, human hunting behavior, prey profitability, herd demography, herd movement, and animal life history as relevant to this main purpose. The model is constructed in the NetLogo modeling platform (Version 6.3.0; Wilensky, 1999).
SONG - Simulation of Network Growth
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013SONG is a simulator designed for simulating the process of transportation network growth.
Model to assess factors that influence local communities compliance with protected areas policies
Gustavo Andrade | Published Monday, November 21, 2011 | Last modified Saturday, April 27, 2013We built a model using R,polr package, to assess 55 published case studies from developing countries to determine what factors influence the level of compliance of local communities with protected area regulations.
Peer reviewed Simulating the Economic Impact of Boko Haram on a Cameroonian Floodplain
Mark Moritz Nathaniel Henry Sarah Laborde | Published Saturday, October 22, 2016 | Last modified Wednesday, June 07, 2017This model examines the potential impact of market collapse on the economy and demography of fishing households in the Logone Floodplain, Cameroon.

Peer reviewed NoD-Neg: A Non-Deterministic model of affordable housing Negotiations
Aya Badawy Nuno Pinto Richard Kingston | Published Sunday, September 08, 2024The Non-Deterministic model of affordable housing Negotiations (NoD-Neg) is designed for generating hypotheses about the possible outcomes of negotiating affordable housing obligations in new developments in England. By outcomes we mean, the probabilities of failing the negotiation and/or the different possibilities of agreement.
The model focuses on two negotiations which are key in the provision of affordable housing. The first is between a developer (DEV) who is submitting a planning application for approval and the relevant Local Planning Authority (LPA) who is responsible for reviewing the application and enforcing the affordable housing obligations. The second negotiation is between the developer and a Registered Social Landlord (RSL) who buys the affordable units from the developer and rents them out. They can negotiate the price of selling the affordable units to the RSL.
The model runs the two negotiations on the same development project several times to enable agents representing stakeholders to apply different negotiation tactics (different agendas and concession-making tactics), hence, explore the different possibilities of outcomes.
The model produces three types of outputs: (i) histograms showing the distribution of the negotiation outcomes in all the simulation runs and the probability of each outcome; (ii) a data file with the exact values shown in the histograms; and (iii) a conversation log detailing the exchange of messages between agents in each simulation run.
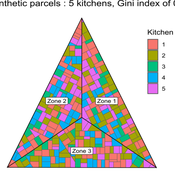
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…
Policy Formulation for Public Administration - Innovation
Bashar Ourabi | Published Tuesday, August 29, 2017 | Last modified Tuesday, August 29, 2017Innovation a byproduct of the intellectual capital, requires a new paradigm for the production constituents. Human Capital HC,Structural capital SC and relational capital RC become key for intellectual capital and consequently for innovation.

Peer reviewed Ache hunting
Kim Hill Marco Janssen | Published Tuesday, August 13, 2013 | Last modified Friday, December 21, 2018Agent-based model of hunting behavior of Ache hunter-gatherers from Paraguay. We evaluate the effect of group size and cooperative hunting

Foundress dilemma model
Marco Janssen Takao Sasaki Zachary Joseph Shaffer Stephen Pratt Brian Haney Jennifer Fewell | Published Thursday, July 28, 2016A haystack-style model of group selection to capture the essential features of colony foundation for queens of the ant based on observation of the ant Pogonomyrmex californicus.
Modeling the decline of labor-sharing in highly variable environments
Marco Janssen Andres Baeza-Castro | Published Tuesday, April 02, 2019The rapid environmental changes currently underway in many dry regions of the world, and the deep uncertainty about their consequences, underscore a critical challenge for sustainability: how to maintain cooperation that ensures the provision of natural resources when the benefits of cooperating are variable, sometimes uncertain, and often limited. We present an agent-based model that simulates the economic decisions of households to engage, or not, in labor-sharing agreements under different scenarios of water supply, water variability, and socio-environmental risk. We formulate the model to investigate the consequences of environmental variability on the fate of labor-sharing agreements between farmers. The economic decisions were implemented in the framework of prospect theory.
Displaying 10 of 972 results for "Ibo van de Poel" clear search