Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 213 results network clear search
Peer reviewed Small-Trade Model
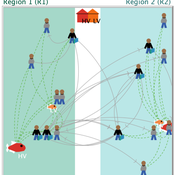
Emilie Lindkvist Maja Schlüter Blanca Gonzalez-Mon Örjan Bodin | Published Wednesday, July 28, 2021The purpose of this model is to understand the role of trade networks and their interaction with different fish resources, for fish provision. The model is developed based on a multi-methods approach, combining agent-based modeling, network analysis and qualitative data based on a small-scale fisheries study case. The model can be used to investigate both how trade network structures are embedded in a social-ecological context and the trade processes that occur within them, to analyze how they lead to emergent outcomes related to the resilience of fish provision. The model processes are informed by qualitative data analysis, and the social network analysis of an empirical fish trade network. The network analysis can be used to investigate diverse network structures to perform model experiments, and their influence on model outcomes.
The main outcomes we study are 1) the overexploitation of fish resources and 2) the availability and variability of fish provision to satisfy different market demands, and 3) individual traders’ fish supply at the micro-level. The model has two types of trader agents, seller and dealer. The model reveals that the characteristics of the trade networks, linked to different trader types (that have different roles in those networks), can affect the resilience of fish provision.

Local extinctions, connectedness, and cultural evolution in structured populations
Luke Premo | Published Tuesday, May 25, 2021This model is designed to address the following research question: How does the amount and topology of intergroup cultural transmission modulate the effect of local group extinction on selectively neutral cultural diversity in a geographically structured population? The experimental design varies group extinction rate, the amount of intergroup cultural transmission, and the topology of intergroup cultural transmission while measuring the effects of local group extinction on long-term cultural change and regional cultural differentiation in a constant-size, spatially structured population. The results show that for most of the intergroup social network topologies tested here, increasing the amount of intergroup cultural transmission (similar to increasing gene flow in a genetic model) erases the negative effect of local group extinction on selectively neutral cultural diversity. The stochastic (i.e., preference attachment) network seems to stand out as an exception.

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.

Dynamics of Public Opinion with Diverse Media and Audiences' Choice
Zhongtian Chen | Published Sunday, April 25, 2021Studies on the fundamental role of diverse media in the evolution of public opinion can protect us from the spreading brainwashing, extremism, and terrorism. Many fear the information cocoon may result in polarization of the public opinion. The model of opinion dynamics that considers different influences and horizons for every individual, and the simulations are based on a real-world social network.
Formal Organization Hierarchy and Informal Networks - "The Company Behind the Org Chart"
Tom Briggs | Published Sunday, April 18, 2021A generalized organizational agent- based model (ABM) containing both formal organizational hierarchy and informal social networks simulates organizational processes that occur over both formal network ties and informal networks.
AIforGoodSimulator - Modeling Covid-19 Spread and Potential Interventions in Refugee Camps
Shyaam Ramkumar Woi Sok Oh | Published Thursday, March 18, 2021The Netlogo model is a conceptualization of the Moria refugee camp, capturing the household demographics of refugees in the camp, a theoretical friendship network based on values, and an abstraction of their daily activities. The model then simulates how Covid-19 could spread through the camp if one refugee is exposed to the virus, utilizing transmission probabilities and the stages of disease progression of Covid-19 from susceptible to exposed to asymptomatic / symptomatic to mild / severe to recovered from literature. The model also incorporates various interventions - PPE, lockdown, isolation of symptomatic refugees - to analyze how they could mitigate the spread of the virus through the camp.
The Effect of Individual and Collective Characteristics on Team Performance: A Model of Networked Agents Engaged in Collective Problem Solving
Amin Boroomand | Published Tuesday, March 16, 2021 | Last modified Monday, July 26, 2021This code is for an agent-based model of collective problem solving in which agents with different behavior strategies, explore the NK landscape while they communicate with their peers agents. This model is based on the famous work of Lazer, D., & Friedman, A. (2007), The network structure of exploration and exploitation.

Peer reviewed An agent-based model for brain drain
Furkan Gürsoy Bertan Badur | Published Wednesday, March 03, 2021 | Last modified Friday, March 12, 2021An agent-based model for the emigration of highly-skilled labour.
We hypothesise that there are two main factors that impact the decision and ability to move abroad: desire to maximise individual utility and network effects. Accordingly, several factors play role in brain drain such as the overall economic and social differences between the home and host countries, people’s ability and capacity to obtain good jobs and start a life abroad, the barriers of moving abroad, and people’s social network who are already working abroad.
Epidemic Simulation with Transportation Simulation
FG Econophysics FG Econophysics | Published Monday, March 01, 2021The Episim framework builds upon the established transportation simulation MATSim and is capable of tracking agents’ movements within a network and thus computing infection chains. Several characteristics of the virus and the environment can be parametred, whilst the infection dynamics is computed based upon a compartment model. The spread of the virus can be mitigated by restricting the agents’ activity in certain places.
SimPioN - Simulating Path dependence in inter-organisational Networks
Nanda Wijermans Frithjof Stöppler | Published Monday, January 11, 2021The SimPioN model aims to abstractly reproduce and experiment with the conditions under which a path-dependent process may lead to a (structural) network lock-in in interorganisational networks.
Path dependence theory is constructed around a process argumentation regarding three main elements: a situation of (at least) initially non-ergodic (unpredictable with regard to outcome) starting conditions in a social setting; these become reinforced by the workings of (at least) one positive feedback mechanism that increasingly reduces the scope of conceivable alternative choices; and that process finally results in a situation of lock-in, where any alternatives outside the already adopted options become essentially impossible or too costly to pursue despite (ostensibly) better options theoretically being available.
The purpose of SimPioN is to advance our understanding of lock-ins arising in interorganisational networks based on the network dynamics involving the mechanism of social capital. This mechanism and the lock-ins it may drive have been shown above to produce problematic consequences for firms in terms of a loss of organisational autonomy and strategic flexibility, especially in high-tech knowledge-intensive industries that rely heavily on network organising.
…
Displaying 10 of 213 results network clear search