Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 113 results for "Steven Dalderop" clear search

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
Social and Task Interdependencies in Innovation Implementation
Spiro Maroulis Uri Wilensky | Published Tuesday, June 04, 2013 | Last modified Tuesday, March 04, 2014This is a model of innovation implementation inside an organization. It characterizes an innovation as a set of distributed and technically interdependent tasks performed by a number of different and socially interconnected frontline workers.
EthnoCultural Tag model (ECT)
Bruce Edmonds David Hales | Published Friday, October 16, 2015 | Last modified Wednesday, May 09, 2018Captures interplay between fixed ethnic markers and culturally evolved tags in the evolution of cooperation and ethnocentrism. Agents evolve cultural tags, behavioural game strategies and in-group definitions. Ethnic markers are fixed.
Reflexivity in a diffusion of innovations model
César García-Díaz Carlos Cordoba | Published Thursday, May 07, 2020In this agent-based model, agents decide to adopt a new product according to a utility function that depends on two kinds of social influences. First, there is a local influence exerted on an agent by her closest neighbors that have already adopted, and also by herself if she feels the product suits her personal needs. Second, there is a global influence which leads agents to adopt when they become aware of emerging trends happening in the system. For this, we endow agents with a reflexive capacity that allows them to recognize a trend, even if they can not perceive a significant change in their neighborhood.
Results reveal the appearance of slowdown periods along the adoption rate curve, in contrast with the classic stylized bell-shaped behavior. Results also show that network structure plays an important role in the effect of reflexivity: while some structures (e.g., scale-free networks) may amplify it, others (e.g., small-world structure) weaken such an effect.
PaCE Austria Pilot Model
Ruth Meyer | Published Tuesday, June 30, 2020The objective of building a social simulation in the Populism and Civic Engagement (PaCE) project is to study the phenomenon of populism by mapping individual level political behaviour and explain the influence of agents on, and their interdependence with the respective political parties. Voters, political parties and – to some extent – the media can be viewed as forming a complex adaptive system, in which parties compete for citizens’ votes, voters decide on which party to vote for based on their respective positions with regard to particular issues, and the media may influence the salience of issues in the public debate.
This is the first version of a model exploring voting behaviour in Austria. It focusses on modelling the interaction of voters and parties in a political landscape; the effects of the media are not yet represented. Austria was chosen as a case study because it has an established populist party (the “Freedom Party” FPO), which has even been part of the government over the years.
Peer reviewed Are Countertrade credits as flexible and efficient as cash? A novel approach to reducing income inequality using countertrade methodology.
Peter Malliaros | Published Monday, May 03, 2021 | Last modified Tuesday, May 11, 2021The impacts of income inequality can be seen everywhere, regardless of the country or the level of economic development. According to the literature review, income inequality has negative impacts in economic, social, and political variables. Notwithstanding of how well or not countries have done in reducing income inequality, none have been able to reduce it to a Gini Coefficient level of 0.2 or less.
This is the promise that a novel approach called Counterbalance Economics (CBE) provides without the need of increased taxes.
Based on the simulation, introducing the CBE into the Australian, UK, US, Swiss or German economies would result in an overall GDP increase of under 1% however, the level of inequality would be reduced from an average of 0.33 down to an average of 0.08. A detailed explanation of how to use the model, software, and data dependencies along with all other requirements have been included as part of the info tab in the model.
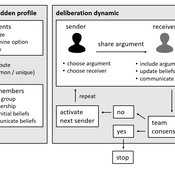
Agent-based model of team decision-making in hidden profile situations
Andreas Flache Jonas Stein Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
Models associated with paper entitled "Polarization in Social Media: A Virtual Worlds-Based Approach"
Sven Banisch Dennis Jacob | Published Thursday, June 22, 2023This model contains MATLAB code describing the virtual worlds framework used in the paper entitled “Polarization in Social Media: A Virtual Worlds-Based Approach.” The parent directory contains driver code for replicating results from the paper. Additionally, the source code is structured by three directories:
- Data Structures: Contains classes and objects used in the code, such as the virtualWorlds.m
- Metrics: Contains code which computes metrics, such as congruentLinks.m
- Visualization: Contains code for generating pictures and plots, such as drawSystemState.m
…

Foundress dilemma model
Marco Janssen Takao Sasaki Zachary Joseph Shaffer Stephen Pratt Brian Haney Jennifer Fewell | Published Thursday, July 28, 2016A haystack-style model of group selection to capture the essential features of colony foundation for queens of the ant based on observation of the ant Pogonomyrmex californicus.
Last Mile Commuter Behavior Model
Dean Massey Moira Zellner Yoram Shiftan Jonathan Levine Maria Arquero | Published Friday, November 07, 2014 | Last modified Friday, November 07, 2014We represent commuters and their preferences for transportation cost, time and safety. Agents assess their options via their preferences, their environment, and the modes available. The model has policy levers to test impact on last-mile problem.
Displaying 10 of 113 results for "Steven Dalderop" clear search