Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 205 results for "Francisco J Miguel" clear search
Peer reviewed Visibility of archaeological social networks
Claudine Gravel-Miguel | Published Sunday, November 26, 2023The purpose of this model is to explore the impact of combining archaeological palimpsests with different methods of cultural transmission on the visibility of prehistoric social networks. Up until recently, Paleolithic archaeologists have relied on stylistic similarities of artifacts to reconstruct social networks. However, this method - which is successfully applied to more recent ceramic assemblages - may not be applicable to Paleolithic assemblages, as several of those consist of palimpsests of occupations. Therefore, this model was created to study how palimpsests of occupation affect our social network reconstructions.
The model simplifies inter-groups interactions between populations who share cultural traits as they produce artifacts. It creates a proxy archaeological record of artifacts with stylistic traits that can then be used to reconstruct interactions. One can thus use this model to compare the networks reconstructed through stylistic similarities with direct contact.
Spatio-Temporal Dynamic of Risk Model
J Jumadi | Published Tuesday, October 22, 2019 | Last modified Sunday, January 05, 2020This model aims to simlulate the dynamic of risk over time and space.
The effect of error on cultural transmission
Claudine Gravel-Miguel | Published Thursday, November 01, 2012 | Last modified Saturday, April 27, 2013This is the replication of the experiment performed by Eerkens and Lipo (2005) to look at the effect of copying errors when specific traits are transferred from an individual to another.
Impact of topography and climate change on Magdalenian social networks
Claudine Gravel-Miguel | Published Monday, September 11, 2017The model presented here was created as part of my dissertation. It aims to study the impacts of topography and climate change on prehistoric networks, with a focus on the Magdalenian, which is dated to between 20 and 14,000 years ago.
Armature distribution within the PaleoscapeABM
Claudine Gravel-Miguel | Published Tuesday, March 23, 2021This is a variant of the PaleoscapeABM model available here written by Wren and Janssen. In this variant, we give projectile weapons to hunter and document where they discard them over time. Discard rate and location are influenced by probabilities of hitting/missing the prey, probabilities of damaging the weapon, and probabilities of carrying back embedded projectile armatures to the habitation camp with the body carcass.

Peer reviewed NetLogo model of USA mass shootings
Smarzhevskiy Ivan | Published Tuesday, September 24, 2019 | Last modified Tuesday, April 14, 2020Is the mass shooter a maniac or a relatively normal person in a state of great stress? According to the FBI report (Silver, J., Simons, A., & Craun, S. (2018). A Study of the Pre-Attack Behaviors of Active Shooters in the United States Between 2000 – 2013. Federal Bureau of Investigation, U.S. Department of Justice,Washington, D.C. 20535.), only 25% of the active shooters were known to have been diagnosed by a mental health professional with a mental illness of any kind prior to the offense.
The main objects of the model are the humans and the guns. The main factors influencing behavior are the population size, the number of people with mental disabilities (“psycho” in the model terminology) per 100,000 population, the total number of weapons (“guns”) in the population, the availability of guns for humans, the intensity of stressors affecting humans and the threshold level of stress, upon reaching which a person commits an act of mass shooting.
The key difference (in the model) between a normal person and a psycho is that a psycho accumulates stressors and, upon reaching a threshold level, commits an act of mass shooting. A normal person is exposed to stressors, but reaching the threshold level for killing occurs only when the simultaneous effect of stressors on him exceeds this level.
The population dynamics are determined by the following factors: average (normally distributed) life expectancy (“life_span” attribute of humans) and population growth with the percentage of newborns set by the value of the TickReprRatio% slider of the current population volume from 16 to 45 years old.Thus, one step of model time corresponds to a year.
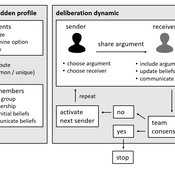
Agent-based model of team decision-making in hidden profile situations
Andreas Flache Jonas Stein Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
ForagerNet3_Demography: A Non-Spatial Model of Hunter-Gatherer Demography
Andrew White | Published Thursday, October 17, 2013 | Last modified Thursday, October 17, 2013ForagerNet3_Demography is a non-spatial ABM for exploring hunter-gatherer demography. Key methods represent birth, death, and marriage. The dependency ratio is an imporant variable in many economic decisions embedded in the methods.
ForagerNet3_Demography_V2
Andrew White | Published Thursday, February 13, 2014ForagerNet3_Demography_V2 is a non-spatial ABM for exploring hunter-gatherer demography. This version (developed from FN3D_V1) contains code for calculating the ratio of old to young adults (the “OY ratio”) in the living and dead populations.
Communication and social change in space and time
Sebastian Kluesener Francesco Scalone Martin Dribe | Published Tuesday, May 17, 2016 | Last modified Friday, October 13, 2017This agent-based model simulates the diffusion of a social change process stratified by social class in space and time which is solely driven social and spatial variation in communication links.
Displaying 10 of 205 results for "Francisco J Miguel" clear search