Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1135 results for "Clint A Penick" clear search

Peer reviewed MOOvPOP
Matthew Gompper Aniruddha Belsare Joshua J Millspaugh | Published Monday, April 10, 2017 | Last modified Saturday, April 19, 2025MOOvPOP is designed to simulate population dynamics (abundance, sex-age composition and distribution in the landscape) of white-tailed deer (Odocoileus virginianus) for a selected sampling region.
RiskNetABM
Birgit Müller Jürgen Groeneveld Karin Frank Meike Will Friederike Lenel | Published Monday, July 20, 2020 | Last modified Monday, May 03, 2021The fight against poverty is an urgent global challenge. Microinsurance is promoted as a valuable instrument for buffering income losses due to health or climate-related risks of low-income households in developing countries. However, apart from direct positive effects they can have unintended side effects when insured households lower their contribution to traditional arrangements where risk is shared through private monetary support.
RiskNetABM is an agent-based model that captures dynamics between income losses, insurance payments and informal risk-sharing. The model explicitly includes decisions about informal transfers. It can be used to assess the impact of insurance products and informal risk-sharing arrangements on the resilience of smallholders. Specifically, it allows to analyze whether and how economic needs (i.e. level of living costs) and characteristics of extreme events (i.e. frequency, intensity and type of shock) influence the ability of insurance and informal risk-sharing to buffer income shocks. Two types of behavior with regard to private monetary transfers are explicitly distinguished: (1) all households provide transfers whenever they can afford it and (2) insured households do not show solidarity with their uninsured peers.
The model is stylized and is not used to analyze a particular case study, but represents conditions from several regions with different risk contexts where informal risk-sharing networks between smallholder farmers are prevalent.
…
Friendship Games Rev 1.0
David Dixon | Published Friday, October 07, 2011 | Last modified Saturday, April 27, 2013A friendship game is a kind of network game: a game theory model on a network. This is a NetLogo model of an agent-based adaptation of “‘Friendship-based’ Games” by PJ Lamberson. The agents reach an equilibrium that depends on the strategy played and the topology of the network.
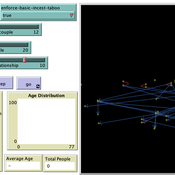
Peer reviewed Monogamous Reproduction in Small Populations and the Enforcement of the Incest Taboo
Ian Stuart | Published Wednesday, January 18, 2023This program was developed to simulate monogamous reproduction in small populations (and the enforcement of the incest taboo).
Every tick is a year. Adults can look for a mate and enter a relationship. Adult females in a Relationship (under the age of 52) have a chance to become pregnant. Everyone becomes not alive at 77 (at which point people are instead displayed as flowers).
User can select a starting-population. The starting population will be adults between the ages of 18 and 42.
…
PopComp
Andre Costopoulos | Published Thursday, December 10, 2020PopComp by Andre Costopoulos 2020
andre.costopoulos@ualberta.ca
Licence: DWYWWI (Do whatever you want with it)
I use Netlogo to build a simple environmental change and population expansion and diffusion model. Patches have a carrying capacity and can host two kinds of populations (APop and BPop). Each time step, the carrying capacity of each patch has a given probability of increasing or decreasing up to a maximum proportion.
…
Peer reviewed ana-wag
Géraldine Abrami Mamadou Diallo Stefano Farolfi Bruno Bonté Nils Ferrand Wanda Aquae Gaudi | Published Monday, February 13, 2017 | Last modified Friday, May 10, 2019The ana-wag model, for Analyse Wat-A-Game (WAG), is a NetLogo version of the WAG role playing game. It enables to model a river catchment with the graphical modelling language WAG and to play it as a network-game (each player is a water user).

WealthDistribRes
Romulus-Catalin Damaceanu | Published Friday, May 04, 2012 | Last modified Saturday, April 27, 2013This model WealthDistribRes can be used to study the distribution of wealth in function of using a combination of resources classified in two renewable and nonrenewable.
Agent-based simulation of discussion processes in risk workshops with quantitative skepticism
Matthias Meyer Clemens Harten Lucia Bellora-Bienengräber | Published Sunday, August 14, 2022The model measures drivers of effectiveness of risk assessments in risk workshops where a calculative culture of quantitative skepticism is present. We model the limits to information transfer, incomplete discussions, group characteristics, and interaction patterns and investigate their effect on risk assessment in risk workshops, in order to contrast results to a previous model focused on a calculative culture of quantitative enthusiasm.
The model simulates a discussion in the context of a risk workshop with 9 participants. The participants use constraint satisfaction networks to assess a given risk individually and as a group.
Social norms and the dominance of Low-doers
Antonio Franco | Published Wednesday, July 13, 2016 | Last modified Sunday, December 02, 2018The code for the paper “Social norms and the dominance of Low-doers”
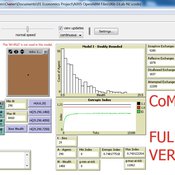
06b EiLab_Model_I_V5.00 NL
Garvin Boyle | Published Saturday, October 05, 2019EiLab - Model I - is a capital exchange model. That is a type of economic model used to study the dynamics of modern money which, strangely, is very similar to the dynamics of energetic systems. It is a variation on the BDY models first described in the paper by Dragulescu and Yakovenko, published in 2000, entitled “Statistical Mechanics of Money”. This model demonstrates the ability of capital exchange models to produce a distribution of wealth that does not have a preponderance of poor agents and a small number of exceedingly wealthy agents.
This is a re-implementation of a model first built in the C++ application called Entropic Index Laboratory, or EiLab. The first eight models in that application were labeled A through H, and are the BDY models. The BDY models all have a single constraint - a limit on how poor agents can be. That is to say that the wealth distribution is bounded on the left. This ninth model is a variation on the BDY models that has an added constraint that limits how wealthy an agent can be? It is bounded on both the left and right.
EiLab demonstrates the inevitable role of entropy in such capital exchange models, and can be used to examine the connections between changing entropy and changes in wealth distributions at a very minute level.
…
Displaying 10 of 1135 results for "Clint A Penick" clear search