Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 43 results Extension clear search
Human-in-the-loop Experiment of the Strategic Coalition Formation using the glove game
Andrew Collins | Published Monday, November 23, 2020 | Last modified Wednesday, June 22, 2022The purpose of the model is to collect information on human decision-making in the context of coalition formation games. The model uses a human-in-the-loop approach, and a single human is involved in each trial. All other agents are controlled by the ABMSCORE algorithm (Vernon-Bido and Collins 2020), which is an extension of the algorithm created by Collins and Frydenlund (2018). The glove game, a standard cooperative game, is used as the model scenario.
The intent of the game is to collection information on the human players behavior and how that compares to the computerized agents behavior. The final coalition structure of the game is compared to an ideal output (the core of the games).
Peer reviewed An Agent-Based Model of Campaign-Based Watershed Management
Samuel Assefa Aad Kessler Luuk Fleskens | Published Monday, September 21, 2020 | Last modified Friday, June 04, 2021The model simulates the national Campaign-Based Watershed Management program of Ethiopia. It includes three agents (farmers, Kebele/ village administrator, extension workers) and the physical environment that interact with each other. The physical environment is represented by patches (fields). Farmers make decisions on the locations of micro-watersheds to be developed, participation in campaign works to construct soil and water conservation structures, and maintenance of these structures. These decisions affect the physical environment or generate model outcomes. The model is developed to explore conditions that enhance outcomes of the program by analyzing the effect on the area of land covered and quality of soil and water conservation structures of (1) enhancing farmers awareness and motivation, (2) establishing and strengthening micro-watershed associations, (3) introducing alternative livelihood opportunities, and (4) enhancing the commitment of local government actors.
Wolf-sheep predation Netlogo model, extended, with foresight
Guido Fioretti Andrea Policarpi | Published Wednesday, September 16, 2020 | Last modified Tuesday, April 13, 2021This model is an extension of the Netlogo Wolf-sheep predation model by U.Wilensky (1997). This extended model studies several different behavioural mechanisms that wolves and sheep could adopt in order to enhance their survivability, and their overall impact on global equilibrium of the system.
Peer review model with heterogeneous grade language
Pablo Lucas Thomas Feliciani Ramanathan Moorthy Kalpana Shankar | Published Thursday, May 07, 2020This ABM re-implements and extends the simulation model of peer review described in Squazzoni & Gandelli (Squazzoni & Gandelli, 2013 - doi:10.18564/jasss.2128) (hereafter: ‘SG’). The SG model was originally developed for NetLogo and is also available in CoMSES at this link.
The purpose of the original SG model was to explore how different author and reviewer strategies would impact the outcome of a journal peer review system on an array of dimensions including peer review efficacy, efficiency and equality. In SG, reviewer evaluation consists of a continuous variable in the range [0,1], and this evaluation scale is the same for all reviewers. Our present extension to the SG model allows to explore the consequences of two more realistic assumptions on reviewer evaluation: (1) that the evaluation scale is discrete (e.g. like in a Likert scale); (2) that there may be differences among their interpretation of the grades of the evaluation scale (i.e. that the grade language is heterogeneous).

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Citizenship competences and conflict resolution styles
Cecilia Avila Manuel Balaguera Valentina Tabares | Published Monday, February 03, 2020This model represents an agent-based social simulation for citizenship competences. In this model people interact by solving different conflicts and a conflict is solved or not considering two possible escenarios: when individual citizenship competences are considered and when not. In both cases the TKI conflict resolution styles are considered. Each conflict has associated a competence and the information about the conflicts and their competences is retrieved from an ontology which was developed in Protégé. To do so, a NetLogo extension was developed using the Java programming language and the JENA API (to make queries over the ontology).
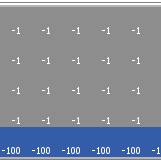
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
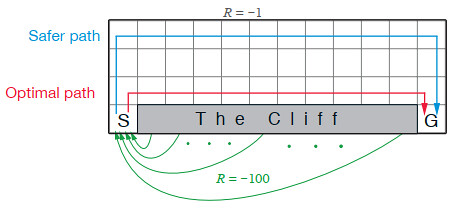
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
PluchinoEtAl_ExtendedByAC
Andre Costopoulos | Published Tuesday, September 03, 2019 | Last modified Friday, January 31, 2020Extension of Pluchino et al.’s 2018 success vs talent model, to allow talented individuals to mitigate unlucky events.
Displaying 10 of 43 results Extension clear search