Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 337 results for "John Nay" clear search
Learning Extension - RAGE RAngeland Grazing Model
Nikita Strelkovskii Cristina I. Apetrei Nikolay Khabarov Valeria Javalera Rincón | Published Saturday, July 22, 2023This is an extension of the original RAGE model (Dressler et al. 2018), where we add learning capabilities to agents, specifically learning-by-doing and social learning (two processes central to adaptive (co-)management).
The extension module is applied to smallholder farmers’ decision-making - here, a pasture (patch) is the private property of the household (agent) placed on it and there is no movement of the households. Households observe the state of the pasture and their neighrbours to make decisions on how many livestock to place on their pasture every year. Three new behavioural types are created (which cannot be combined with the original ones): E-RO (baseline behaviour), E-LBD (learning-by-doing) and E-RO-SL1 (social learning). Similarly to the original model, these three types can be compared regarding long-term social-ecological performance. In addition, a global strategy switching option (corresponding to double-loop learning) allows users to study how behavioural strategies diffuse in a heterogeneous population of learning and non-learning agents.
An important modification of the original model is that extension agents are heterogeneous in how they deal with uncertainty. This is represented by an agent property, called the r-parameter (household-risk-att in the code). The r-parameter is catch-all for various factors that form an agent’s disposition to act in a certain way, such as: uncertainty in the sensing (partial observability of the resource system), noise in the information received, or an inherent characteristic of the agent, for instance, their risk attitude.
Urban Teacher Lifecycle and Mobility
Yevgeny Patarakin | Published Wednesday, July 23, 2025This agent-based model simulates the lifecycle, movement, and satisfaction of teachers within an urban educational system composed of multiple universities and schools. Each teacher agent transitions through several possible roles: newcomer, university student, unemployed graduate, and employed teacher. Teachers’ pathways are shaped by spatial configuration, institutional capacities, individual characteristics, and dynamic interactions with schools and universities. Universities are assigned spatial locations with a controllable level of centralization and are characterized by academic ratings, capacity, and alumni records. Schools are distributed throughout the city, each with a limited number of vacancies, hiring requirements, and offered salaries. Teachers apply to universities based on the alignment of their personal academic profiles with institutional ratings, pursue studies, and upon graduation become candidates for employment at schools.
The employment process is driven by a decentralized matching of teacher expectations and school offers, taking into account factors such as salary, proximity, and peer similarity. Teachers’ satisfaction evolves over time, reflecting both institutional characteristics and the composition of their colleagues; low satisfaction may prompt teachers to transfer between schools within their mobility radius. Mortality and teacher attrition further shape workforce dynamics, leading to continuous recruitment of newcomers to maintain a stable population. The model tracks university reputation through the academic performance and number of alumni, and visualizes key metrics including teacher status distribution, school staffing, university alumni counts, and overall satisfaction. This structure enables the exploration of policy interventions, hiring and training strategies, and the impact of spatial and institutional design on the allocation, retention, and happiness of urban educational staff.
We propose here a computational model of school segregation that is aligned with a corresponding Schelling-type model of residential segregation. To adapt the model for application to school segregation, we move beyond previous work by combining two preference arguments in modeling parents’ school choice, preferences for the ethnic composition of a school and preferences for minimizing the travelling distance to the school.

The role of spatial foresight in models of hominin dispersal
Colin Wren | Published Monday, February 24, 2014 | Last modified Monday, July 14, 2014The natural selection of foresight, an accuracy at assess the environment, under degrees of environmental heterogeneity. The model is designed to connect local scale mobility, from foraging, with the global scale phenomenon of population dispersal.
The Pampas Model: An agent-based model of agricultural systems in the Argentinean Pampas
Michael North Federico Bert Guillermo P Podestá Santiago L Rovere Charles Macal | Published Tuesday, July 16, 2013 | Last modified Tuesday, February 17, 2015The Pampas Model is an Agent-Based Model intended to explore the dynamics of structural and land use changes in agricultural systems of the Argentine Pampas in response to climatic, technological economic, and political drivers.
SLUCEII LUXE (Land Use in an eXurban Environment)
Qingxu Huang Rick L Riolo Shipeng Sun Derek Robinson Dawn Parker Tatiana Filatova Meghan Hutchins Dan Brown | Published Tuesday, September 10, 2013 | Last modified Saturday, October 22, 2022LUXE is a land-use change model featuring different levels of land market implementation. It integrates utility measures, budget constraints, competitive bidding, and market interactions to model land-use change in exurban environment.
Cultural Group Selection of Sustainable Institutions
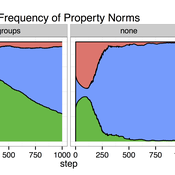
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.
An Agent-Based DSS for Word-of-Mouth Programs in Freemium Apps
Manuel Chica | Published Monday, September 05, 2016An agent-based framework that aggregates social network-level individual interactions to run targeting and rewarding programs for a freemium social app. Git source code in https://bitbucket.org/mchserrano/socialdynamicsfreemiumapps

Peer reviewed NetLogo model of USA mass shootings
Smarzhevskiy Ivan | Published Tuesday, September 24, 2019 | Last modified Tuesday, April 14, 2020Is the mass shooter a maniac or a relatively normal person in a state of great stress? According to the FBI report (Silver, J., Simons, A., & Craun, S. (2018). A Study of the Pre-Attack Behaviors of Active Shooters in the United States Between 2000 – 2013. Federal Bureau of Investigation, U.S. Department of Justice,Washington, D.C. 20535.), only 25% of the active shooters were known to have been diagnosed by a mental health professional with a mental illness of any kind prior to the offense.
The main objects of the model are the humans and the guns. The main factors influencing behavior are the population size, the number of people with mental disabilities (“psycho” in the model terminology) per 100,000 population, the total number of weapons (“guns”) in the population, the availability of guns for humans, the intensity of stressors affecting humans and the threshold level of stress, upon reaching which a person commits an act of mass shooting.
The key difference (in the model) between a normal person and a psycho is that a psycho accumulates stressors and, upon reaching a threshold level, commits an act of mass shooting. A normal person is exposed to stressors, but reaching the threshold level for killing occurs only when the simultaneous effect of stressors on him exceeds this level.
The population dynamics are determined by the following factors: average (normally distributed) life expectancy (“life_span” attribute of humans) and population growth with the percentage of newborns set by the value of the TickReprRatio% slider of the current population volume from 16 to 45 years old.Thus, one step of model time corresponds to a year.
RecovUS: An Agent-Based Model of Post-Disaster Household Recovery
Saeed Moradi | Published Thursday, July 30, 2020The purpose of this model is to explain the post-disaster recovery of households residing in their own single-family homes and to predict households’ recovery decisions from drivers of recovery. Herein, a household’s recovery decision is repair/reconstruction of its damaged house to the pre-disaster condition, waiting without repair/reconstruction, or selling the house (and relocating). Recovery drivers include financial conditions and functionality of the community that is most important to a household. Financial conditions are evaluated by two categories of variables: costs and resources. Costs include repair/reconstruction costs and rent of another property when the primary house is uninhabitable. Resources comprise the money required to cover the costs of repair/reconstruction and to pay the rent (if required). The repair/reconstruction resources include settlement from the National Flood Insurance (NFI), Housing Assistance provided by the Federal Emergency Management Agency (FEMA-HA), disaster loan offered by the Small Business Administration (SBA loan), a share of household liquid assets, and Community Development Block Grant Disaster Recovery (CDBG-DR) fund provided by the Department of Housing and Urban Development (HUD). Further, household income determines the amount of rent that it can afford. Community conditions are assessed for each household based on the restoration of specific anchors. ASNA indexes (Nejat, Moradi, & Ghosh 2019) are used to identify the category of community anchors that is important to a recovery decision of each household. Accordingly, households are indexed into three classes for each of which recovery of infrastructure, neighbors, or community assets matters most. Further, among similar anchors, those anchors are important to a household that are located in its perceived neighborhood area (Moradi, Nejat, Hu, & Ghosh 2020).
Displaying 10 of 337 results for "John Nay" clear search