Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 276 results for "Ted C. Rogers" clear search
A spatial model of resource-consumer dynamics
Arend Ligtenberg Guus Ten Broeke George Ak Van Voorn Jaap Molenaar | Published Wednesday, January 11, 2017 | Last modified Thursday, September 17, 2020The model simulates agents in a spatial environment competing for a common resource that grows on patches. The resource is converted to energy, which is needed for performing actions and for surviving.
Agent-based model of sexual partnership
Andrea Knittel | Published Monday, December 05, 2011 | Last modified Saturday, April 27, 2013In this model agents meet, evaluate one another, decide whether or not to date, if and when to become sexual partners, and when to break up.
SimPLS - The PLS Agent
Iris Lorscheid Sandra Schubring Matthias Meyer Christian Ringle | Published Monday, April 18, 2016 | Last modified Tuesday, May 17, 2016The simulation model SimPLS shows an application of the PLS agent concept, using SEM as empirical basis for the definition of agent architectures. The simulation model implements the PLS path model TAM about the decision of using innovative products.

Peer reviewed Infectious diseases model for mixed-methods research chapter
Mark Moritz Ian M Hamilton Chelsea E Hunter Daniel C Peart | Published Sunday, January 30, 2022The purpose of this curricular model is to teach students the basics of modeling complex systems using agent-based modeling. It is a simple SIR model that simulates how a disease spreads through a population as its members change from susceptible to infected to recovered and then back to susceptible. The dynamics of the model are such that there are multiple emergent outcomes depending on the parameter settings, initial conditions, and chance.
The curricular model can be used with the chapter Agent-Based Modeling in Mixed Methods Research (Moritz et al. 2022) in the Handbook of Teaching Qualitative & Mixed Methods (Ruth et al. 2022).
The instructional videos can be accessed on YouTube: Video 1 (https://youtu.be/32_JIfBodWs); Video 2 (https://youtu.be/0PK_zVKNcp8); and Video 3 (https://youtu.be/0bT0_mYSAJ8).
A Complex Model of Voter Turnout
Bruce Edmonds Laurence Lessard-Phillips Ed Fieldhouse | Published Monday, October 13, 2014 | Last modified Tuesday, August 18, 2015This is a complex “Data Integration Model”, following a “KIDS” rather than a “KISS” methodology - guided by the available evidence. It looks at the complex mix of social processes that may determine why people vote or not.
Value Chain Marketing (VCM)
Stephanie Hintze | Published Monday, April 14, 2014 | Last modified Thursday, October 16, 2014Inspired by the SKIN model, the basic concept here is to model the acceptance and implementation of supplier innovations. This model includes three types of agents comprising suppliers, manufacturers and applicators.
ReMoTe-S. Residential Mobility of Tenants in Switzerland: an agent-based model
Claudia Binder Anna Pagani Francesco Ballestrazzi Emanuele Massaro | Published Friday, April 01, 2022ReMoTe-S is an agent-based model of the residential mobility of Swiss tenants. Its goal is to foster a holistic understanding of the reciprocal influence between households and dwellings and thereby inform a sustainable management of the housing stock. The model is based on assumptions derived from empirical research conducted with three housing providers in Switzerland and can be used mainly for two purposes: (i) the exploration of what if scenarios that target a reduction of the housing footprint while accounting for households’ preferences and needs; (ii) knowledge production in the field of residential mobility and more specifically on the role of housing functions as orchestrators of the relocation process.
ABM Simulation of Transition from Late Longshan Cultures to Early Erlitou Culture
Carmen Iasiello | Published Sunday, November 26, 2023Within the archeological record for Bronze Age Chinese culture, there continues to be a gap in our understanding of the sudden rise of the Erlitou State from the previous late Longshan chiefdoms. In order to examine this period, I developed and used an agent-based model (ABM) to explore possible socio-politically relevant hypotheses for the gap between the demise of the late Longshan cultures and rise of the first state level society in East Asia. I tested land use strategy making and collective action in response to drought and flooding scenarios, the two plausible environmental hazards at that time. The model results show cases of emergent behavior where an increase in social complexity could have been experienced if a catastrophic event occurred while the population was sufficiently prepared for a different catastrophe, suggesting a plausible lead for future research into determining the life of the time period.
The ABM published here was originally developed in 2016 and its results published in the Proceedings of the 2017 Winter Simulation Conference.
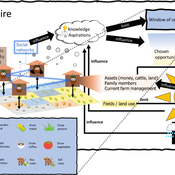
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
AMIRIS
Ulrich Frey Felix Nitsch Christoph Schimeczek Johannes Kochems Kristina Nienhaus Evelyn Sperber Aboubakr Achraf El Ghazi Seyedfarzad Sarfarazi | Published Thursday, February 03, 2022AMIRIS is the Agent-based Market model for the Investigation of Renewable and Integrated energy Systems.
It is an agent-based simulation of electricity markets and their actors.
AMIRIS enables researches to analyse and evaluate energy policy instruments and their impact on the actors involved in the simulation context.
Different prototypical agents on the electricity market interact with each other, each employing complex decision strategies.
AMIRIS allows to calculate the impact of policy instruments on economic performance of power plant operators and marketers.
…
Displaying 10 of 276 results for "Ted C. Rogers" clear search