Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 233 results for "G M Leighton" clear search
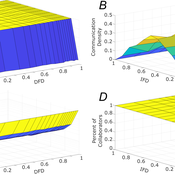
Role of Diversity in Team Performance: the Case of Missing Expertise, an Agent Based Simulations
Tamás Kiss | Published Friday, December 29, 2023This ABM simulates problem solving agents as they work on a set of tasks. Each agent has a trait vector describing their skills. Two agents might form a collaboration if their traits are similar enough. Tasks are defined by a component vector. Agents work on tasks by decreasing tasks’ component vectors towards zero.
The simulation generates agents with given intrapersonal functional diversity (IFD), and dominant function diversity (DFD), and a set of random tasks and evaluates how agents’ traits influence their level of communication and the performance of a team of agents.
Modeling results highlight the importance of the distributions of agents’ properties forming a team, and suggests that for a thorough description of management teams, not only diversity measures based on individual agents, but an aggregate measure is also required.
…
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
SeaROOTS ABM: Simulating Artificial Hominins Maritime Mobility at Inner Ionian, Greece
Angelos Chliaoutakis | Published Wednesday, May 29, 2024SeaROOTS ABM is a quite generic agent-based modeling system, for simulating and evaluating potential terrestrial and maritime mobility of artificial hominin groups, configured by available archaeological data and hypotheses. Necessary bathymetric, geomorphological and paleoenvironmental data are combined in order to reconstruct paleoshorelines for the study area and produce an archaeologically significant agent environment. Paleoclimatic and archaeological data are incorporated in the ABM in order to simulate maritime crossings and assess the emergent patterns of interaction between human agency and the sea.
SeaROOTS agent-based system includes completely autonomous, utility-based agents (Chliaoutakis & Chalkiadakis 2016), representing artificial hominin groups, with partial knowledge of their environment, for simulating their evolution and potential maritime mobility, utilizing alternative Least Cost Path analysis modeling techniques (Gustas & Supernant 2017, Gravel-Miguel & Wren 2021). Two groups of hominins, Neanderthals and Homo sapiens, are chosen in order to study the challenges and actions employed as a response to the fluctuating sea-levels, as well as probability scenarios with respect to sea-crossings via buoyant vessels (rafting) or the human body itself (swimming). SeaROOTS ABM aims to simulate various scenarios and investigate the degree climatic fluctuations influenced such activities and interactions in the Middle Paleolithic period.
The model focuses on simulating potential terrestrial and maritime routes, explore the interactions and relations between autonomous agents and their environment, as well as to test specific research questions; for example, when and under what conditions would Middle Paleolithic hominins be more likely to attempt a crossing and successfully reach the islands? By which agent type (Sapiens or Neanderthals) and how (e.g. swimming or by sea-vessels) could such short sea crossings be (mostly) attempted, and which (sea) routes were usually considered by the agents? When does a sea-crossing become a choice and when is it a result of forced migration, i.e. disaster- or conflict-induced displacement? Results show that the dynamic marine environment of the Inner Ionian, our case study in this work, played an important role in their decision-making process.

ABM for Underwater optical wireless communication in a water tank
Mohamed ABID | Published Sunday, May 29, 2022This model simulates the propagation of photons in a water tank. A source of light emits an impulse of photons with equal energy represented by yellow dots. These photons are then scattered by water particles before possibly reaching the photo-detector represented by a gray line. Different types of water are considered. For each one of them we calculate the total received energy.
The water tank is represented by a blue rectangle with fixed dimensions. It’s exposed to the air interface and has totally absorbent barriers. Four types of water are supported. Each one is characterized by its absorption and scattering coefficients.
At the source, the photons are generated uniformly with a random direction within the beamwidth. Each photon travels a random distance drawn from a distribution depending on the water characteristics before encountering a water particle.
Based on the updated position of the photon, three situations may occur:
-The photon hits the barrier of the tank on its trajectory. In this case it’s considered as lost since the barriers are assumed totally absorbent.
…

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
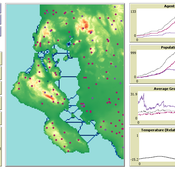
Geographic Expansion Model (GEM)
Sean Bergin | Published Friday, February 28, 2020The purpose of this model is to explore the importance of geographic factors to the settlement choices of early Neolithic agriculturalists. In the model, each agriculturalist spreads to one of the best locations within a modeler specified radius. The best location is determined by choosing either one factor such as elevation or slope; or by ranking geographic factors in order of importance.
JLootBox: An Agent-Based Model of Social Influence and Gambling in Online Video Games
Lila Zayed | Published Friday, May 06, 2022This model aims to explore how gambling-like behavior can emerge in loot box spending within gaming communities. A loot box is a purchasable mystery box that randomly awards the player a series of in-game items. Since the contents of the box are largely up to chance, many players can fall into a compulsion loop of purchasing, as the fear of missing out and belief in the gambler’s fallacy allow one to rationalize repeated purchases, especially when one compares their own luck to others. To simulate this behavior, this model generates players in different network structures to observe how factors such as network connectivity, a player’s internal decision making strategy, or even common manipulations games use these days may influence a player’s transactions.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025 | Last modified Tuesday, March 24, 2026The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
MiniDemographicABM.jl: A simplified agent-based demographic model of the UK
Atiyah Elsheikh | Published Friday, July 28, 2023 | Last modified Tuesday, December 12, 2023This package implements a simplified artificial agent-based demographic model of the UK. Individuals of an initial population are subject to ageing, deaths, births, divorces and marriages. A specific case-study simulation is progressed with a user-defined simulation fixed step size on a hourly, daily, weekly, monthly basis or even an arbitrary user-defined clock rate. While the model can serve as a base model to be adjusted to realistic large-scale socio-economics, pandemics or social interactions-based studies mainly within a demographic context, the main purpose of the model is to explore and exploit capabilities of the state-of-the-art Agents.jl Julia package as well as other ecosystem of Julia packages like GlobalSensitivity.jl. Code includes examples for evaluating global sensitivity analysis using Morris and Sobol methods and local sensitivity analysis using OFAT and OAT methods. Multi-threaded parallelization is enabled for improved runtime performance.
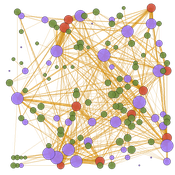
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
Displaying 10 of 233 results for "G M Leighton" clear search