Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 269 results for "David Moore" clear search
Peer reviewed E³-MAN. An Institutionally-guided multi-agent. Model for fair and efficient negotiation.
José luis bustelo | Published Monday, September 01, 2025Negotiation plays a fundamental role in shaping human societies, underpinning conflict resolution, institutional design, and economic coordination. This article introduces E³-MAN, a novel multi-agent model for negotiation that integrates individual utility maximization with fairness and institutional legitimacy. Unlike classical approaches grounded solely in game theory, our model incorporates Bayesian opponent modeling, transfer learning from past negotiation domains, and fallback institutional rules to resolve deadlocks. Agents interact in dynamic environments characterized by strategic heterogeneity and asymmetric information, negotiating over multidimensional issues under time constraints. Through extensive simulation experiments, we compare E³-MAN against the Nash bargaining solution and equal-split baselines using key performance metrics: utilitarian efficiency, Nash social welfare, Jain fairness index, Gini coefficient, and institutional compliance. Results show that E³-MAN achieves near-optimal efficiency while significantly improving distributive equity and agreement stability. A legal application simulating multilateral labor arbitration demonstrates that institutional default rules foster more balanced outcomes and increase negotiation success rates from 58% to 98%. By combining computational intelligence with normative constraints, this work contributes to the growing field of socially aware autonomous agents. It offers a virtual laboratory for exploring how simple institutional interventions can enhance justice, cooperation, and robustness in complex socio-legal systems.
The Targeted Subsidies Plan Model
Hassan Bashiri | Published Thursday, September 21, 2023The targeted subsidies plan model is based on the economic concept of targeted subsidies.
The targeted subsidies plan model simulates the distribution of subsidies among households in a community over several years. The model assumes that the government allocates a fixed amount of money each year for the purpose of distributing cash subsidies to eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount. The model simulates the impact of the subsidy distribution process on the income and property of households in the community over time.
The model simulates a community of 230 households, each with a household income and wealth that follows a power-law distribution. The number of household members is modeled by a normal distribution. The model allocates a fixed amount of money each year for the purpose of distributing cash subsidies among eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount.
The model runs for a period of 10 years, with the subsidy distribution process occurring every month. The subsidy received by each household is assumed to be spent, and a small portion may be saved and added to the household’s property. At the end of each year, the grouping of households based on income and assets is redone, and a number of families may be moved from one group to another based on changes in their income and property.
…
Social and ecological feedback in greening behavior
Athena Aktipis | Published Thursday, February 19, 2015We construct an agent-based model to investigate and understand the roles of green attachment, engagement in local ecological investment (i.e., greening), and social feedback.
(De-)Stabilising effect of diffusions
Julia Kasmire Bert Van Meeuwen Cornelis Eikelboom | Published Tuesday, August 11, 2015What is stable: the large but coordinated change during a diffusion or the small but constant and uncoordinated changes during a dynamic equilibrium? This agent-based model of a diffusion creates output that reveal insights for system stability.

Walk Away in groups
Athena Aktipis | Published Thursday, March 17, 2016This NetLogo model implements the Walk Away strategy in a spatial public goods game, where individuals have the ability to leave groups with insufficient levels of cooperation.
THE STATUS ARENA
Gert Jan Hofstede Jillian Student Mark R Kramer | Published Wednesday, June 08, 2016 | Last modified Tuesday, January 09, 2018Status-power dynamics on a playground, resulting in a status landscape with a gender status gap. Causal: individual (beauty, kindness, power), binary (rough-and-tumble; has-been-nice) or prior popularity (status). Cultural: acceptability of fighting.
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Gert Jan Hofstede Mark R Kramer Sebastian Fajardo Andrés Bernal Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.
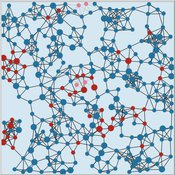
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
Construction and Demolition model to track material flows and embodied carbon
Jonathan Edgardo Cohen | Published Monday, September 30, 2024Reusing existing material stocks in developed built environments can significantly reduce the environmental footprint of the construction and demolition sector. However, material reuse in urban areas presents technical, temporal, and geographical challenges. Although a better understanding of spatial and temporal changes in material stocks could improve city resource management, limited scientific contributions have addressed this challenge.
This study details the steps followed in developing a spatially explicit rule-based simulation of materials stock. The simulation provides a proof of concept by incorporating the spatial and temporal dimensions of construction and demolition activities to analyse how various urban parameters determine material flows and embodied carbon in urban areas. The model explores the effects of 1) re-using recycled materials, 2) demolitions, 3) renovations and 4) various building typologies.
To showcase the model’s capabilities, the residential building stock of Gothenburg City is used as a case study, and eight building materials are tracked. Environmental impacts (A1-A3) are calculated with embodied carbon factors. The main parameters are explored in a baseline scenario. Then, a second scenario focuses on a hypothetical policy that promotes improvements in building energy performance.
The simulation can be expanded to include more materials and built environment assets and allows for future explorations on, for example, the role of logistics, the implementation of recycling or reuse stations, and, in general, supporting sustainable and circular strategies from the construction sector.
Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Displaying 10 of 269 results for "David Moore" clear search