Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 235 results for "Andrea Kaim" clear search
Modeling information Asymmetries in Tourism
Jacopo A. Baggio Rodolfo Baggio | Published Monday, January 09, 2012 | Last modified Saturday, April 27, 2013A very simple model elaborated to explore what may happens when buyers (travelers) have more information than sellers (tourist destinations)
Change and Senescence
André Martins | Published Tuesday, November 10, 2020Agers and non-agers agent compete over a spatial landscape. When two agents occupy the same grid, who will survive is decided by a random draw where chances of survival are proportional to fitness. Agents have offspring each time step who are born at a distance b from the parent agent and the offpring inherits their genetic fitness plus a random term. Genetic fitness decreases with time, representing environmental change but effective non-inheritable fitness can increase as animals learn and get bigger.
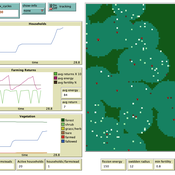
Swidden farming by individual households
C Michael Barton | Published Sunday, April 27, 2008 | Last modified Saturday, April 27, 2013Swidden Farming is designed to explore the dynamics of agricultural land management strategies.
The AgriculTural LandscApe Simulator (ATLAS)
Hugo Thierry Claude Monteil Aude Vialatte Jean-Philippe Choisis Benoit Gaudou Hazel Parry | Published Monday, January 30, 2017 | Last modified Wednesday, May 10, 2017The spatially-explicit AgriculTuralLandscApe Simulator (ATLAS) simulates realistic spatial-temporal crop availability at the landscape scale through crop rotations and crop phenology.
The Pampas Model: An agent-based model of agricultural systems in the Argentinean Pampas
Michael North Federico Bert Guillermo P Podestá Santiago L Rovere Charles Macal | Published Tuesday, July 16, 2013 | Last modified Tuesday, February 17, 2015The Pampas Model is an Agent-Based Model intended to explore the dynamics of structural and land use changes in agricultural systems of the Argentine Pampas in response to climatic, technological economic, and political drivers.
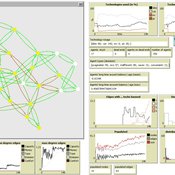
Simulation of the Governance of Complex Systems
Fabian Adelt Johannes Weyer Robin D Fink Andreas Ihrig | Published Monday, December 18, 2017 | Last modified Friday, March 02, 2018Simulation-Framework to study the governance of complex, network-like sociotechnical systems by means of ABM. Agents’ behaviour is based on a sociological model of action. A set of basic governance mechanisms helps to conduct first experiments.
Retention in Higher Education: An Agent-Based Model of Social Interactions and Motivated Agent Behavior
Andrew Crooks Amira Al-Khulaidy Stine | Published Wednesday, October 23, 2024Educational attainment and student retention in higher education are two of the main focuses of higher education research. Institutions in the U.S. are constantly looking for ways to identify areas of improvement across different aspects of the student experience on university campuses. This paper combines Department of Education data, U.S. Census data, and higher education theory on student retention, to build an agent-based model of student behavior.
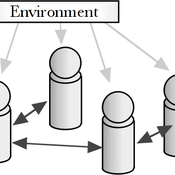
Political Participation
Didier Ruedin | Published Saturday, April 12, 2014 | Last modified Sunday, September 28, 2025Implementation of Milbrath’s (1965) model of political participation. Individual participation is determined by stimuli from the political environment, interpersonal interaction, as well as individual characteristics.
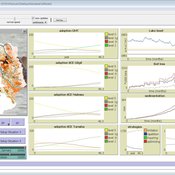
CONSERVAT
Pieter Van Oel | Published Monday, April 13, 2015The CONSERVAT model evaluates the effect of social influence among farmers in the Lake Naivasha basin (Kenya) on the spatiotemporal diffusion pattern of soil conservation effort levels and the resulting reduction in lake sedimentation.
Peer reviewed Labor and environment in global value chains: An evolutionary policy study with a three-sector and two-region agent-based macroeconomic model
Lena Gerdes Manuel Scholz-Wäckerle Bernhard Rengs | Published Wednesday, December 22, 2021With this model, we investigate resource extraction and labor conditions in the Global South as well as implications for climate change originating from industry emissions in the North. The model serves as a testbed for simulation experiments with evolutionary political economic policies addressing these issues. In the model, heterogeneous agents interact in a self-organizing and endogenously developing economy. The economy contains two distinct regions – an abstract Global South and Global North. There are three interlinked sectors, the consumption good–, capital good–, and resource production sector. Each region contains an independent consumption good sector, with domestic demand for final goods. They produce a fictitious consumption good basket, and sell it to the households in the respective region. The other sectors are only present in one region. The capital good sector is only found in the Global North, meaning capital goods (i.e. machines) are exclusively produced there, but are traded to the foreign as well as the domestic market as an intermediary. For the production of machines, the capital good firms need labor, machines themselves and resources. The resource production sector, on the other hand, is only located in the Global South. Mines extract resources and export them to the capital firms in the North. For the extraction of resources, the mines need labor and machines. In all three sectors, prices, wages, number of workers and physical capital of the firms develop independently throughout the simulation. To test policies, an international institution is introduced sanctioning the polluting extractivist sector in the Global South as well as the emitting industrial capital good producers in the North with the aim of subsidizing innovation reducing environmental and social impacts.
Displaying 10 of 235 results for "Andrea Kaim" clear search