Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 186 results for "Wil Hennen" clear search
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.
Coalitions in Networked Innovation
Rory Sie Peter Sloep Marlies Bitter-Rijpkema | Published Tuesday, February 11, 2014A first version of a model that describes how coalitions are formed during open, networked innovation
Friendship Games Rev 1.0
David Dixon | Published Friday, October 07, 2011 | Last modified Saturday, April 27, 2013A friendship game is a kind of network game: a game theory model on a network. This is a NetLogo model of an agent-based adaptation of “‘Friendship-based’ Games” by PJ Lamberson. The agents reach an equilibrium that depends on the strategy played and the topology of the network.
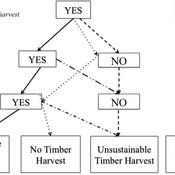
Private forest owner management behavior using social interactions, information flow, and peer-to-peer n
Jessica Leahy Emily Silver Huff Aaron R Weiskittel Caroline L Noblet David Hiebeler | Published Tuesday, October 13, 2015This theoretical model includes forested polygons and three types of agents: forest landowners, foresters, and peer leaders. Agent rules and characteristics were parameterized from existing literature and an empirical survey of forest landowners.
Peer reviewed Viable North Sea (ViNoS): A NetLogo Agent-based Model of German Small-scale Fisheries
Wolfgang Nikolaus Probst Jieun Seo Jürgen Scheffran Carsten Lemmen Sascha Hokamp Verena Mühlberger Serra Örey | Published Thursday, May 25, 2023 | Last modified Tuesday, December 05, 2023Viable North Sea (ViNoS) is an Agent-based Model of the German North Sea Small-scale Fisheries in a Social-Ecological Systems framework focussing on the adaptive behaviour of fishers facing regulatory, economic, and resource changes. Small-scale fisheries are an important part both of the cultural perception of the German North Sea coast and of its fishing industry. These fisheries are typically family-run operations that use smaller boats and traditional fishing methods to catch a variety of bottom-dwelling species, including plaice, sole, and brown shrimp. Fisheries in the North Sea face area competition with other uses of the sea – long practiced ones like shipping, gas exploration and sand extractions, and currently increasing ones like marine protection and offshore wind farming. German authorities have just released a new maritime spatial plan implementing the need for 30% of protection areas demanded by the United Nations High Seas Treaty and aiming at up to 70 GW of offshore wind power generation by 2045. Fisheries in the North Sea also have to adjust to the northward migration of their established resources following the climate heating of the water. And they have to re-evaluate their economic balance by figuring in the foreseeable rise in oil price and the need for re-investing into their aged fleet.
Peer reviewed Horse population dynamics
Nika Galic | Published Tuesday, November 12, 2013 | Last modified Wednesday, October 29, 2014This model investigates the link between prescribed growth in body size, population dynamics and density dependence through population feedback on available resources.
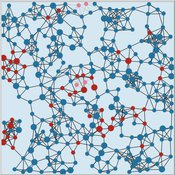
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025 | Last modified Tuesday, March 24, 2026The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
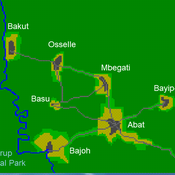
A stylized scale model to codesign with villagers an agent-based model of bushmeat hunting in the periphery of Korup National Park (Cameroon)

Peer reviewed Agent-based model to simulate equilibria and regime shifts emerged in lake ecosystems
no contributors listed | Published Tuesday, January 25, 2022(An empty output folder named “NETLOGOexperiment” in the same location with the LAKEOBS_MIX.nlogo file is required before the model can be run properly)
The model is motivated by regime shifts (i.e. abrupt and persistent transition) revealed in the previous paleoecological study of Taibai Lake. The aim of this model is to improve a general understanding of the mechanism of emergent nonlinear shifts in complex systems. Prelimnary calibration and validation is done against survey data in MLYB lakes. Dynamic population changes of function groups can be simulated and observed on the Netlogo interface.
Main functional groups in lake ecosystems were modelled as super-individuals in a space where they interact with each other. They are phytoplankton, zooplankton, submerged macrophyte, planktivorous fish, herbivorous fish and piscivorous fish. The relationships between these functional groups include predation (e.g. zooplankton-phytoplankton), competition (phytoplankton-macrophyte) and protection (macrophyte-zooplankton). Each individual has properties in size, mass, energy, and age as physiological variables and reproduce or die according to predefined criteria. A system dynamic model was integrated to simulate external drivers.
Set biological and environmental parameters using the green sliders first. If the data of simulation are to be logged, set “Logdata” as true and input the name of the file you want the spreadsheet(.csv) to be called. You will need create an empty folder called “NETLOGOexperiment” in the same level and location with the LAKEOBS_MIX.nlogo file. Press “setup” to initialise the system and “go” to start life cycles.
Displaying 10 of 186 results for "Wil Hennen" clear search