Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 195 results for "Ingo Kowarik" clear search
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.
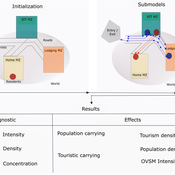
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.
The Urban Drought Nexus Tool
Roger Cremades Muhamad Khairulbahri | Published Thursday, December 14, 2023The “Urban Drought Nexus Tool” is a system dynamics model, aiming to facilitate the co-development of climate services for cities under increasing droughts. The tool integrates multiple types of information and still can be applied to other case studies with minimal adjustments on the parameters of land use, water consumption and energy use in the water sector. The tool needs hydrological projections under climate scenarios to evaluate climatic futures, and requires the co-creation of socio-economic future scenarios with local stakeholders. Thus it is possible to provide specific information about droughts taking into account future water availability and future water consumption. Ultimately, such complex system as formed by the water-energy-land nexus can be reduced to single variables of interest, e.g. the number of events with no water available in the future and their length, so that the complexities are reduced and the results can be conveyed to society in an understandable way, including the communication of uncertainties. The tool and an explanatory guide in pdf format are included. Planned further developments include calibrating the system dynamics model with the social dynamics behind each flow with agent-based models.
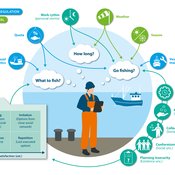
Peer reviewed FISHCODE - FIsheries Simulation with Human COmplex DEcision-making
Birgit Müller Gunnar Dressler Jonas Letschert Christian Möllmann Vanessa Stelzenmüller | Published Monday, August 05, 2024FIsheries Simulation with Human COmplex DEcision-making (FISHCODE) is an agent-based model to depict and analyze current and future spatio-temporal dynamics of three German fishing fleets in the southern North Sea. Every agent (fishing vessel) makes daily decisions about if, what, and how long to fish. Weather, fuel and fish prices, as well as the actions of their colleagues influence agents’ decisions. To combine behavioral theories and enable agents to make dynamic decision, we implemented the Consumat approach, a framework in which agents’ decisions vary in complexity and social engagement depending on their satisfaction and uncertainty. Every agent has three satisfactions and two uncertainties representing different behavioral aspects, i.e. habitual behavior, profit maximization, competition, conformism, and planning insecurity. Availability of extensive information on fishing trips allowed us to parameterize many model parameters directly from data, while others were calibrated using pattern oriented modelling. Model validation showed that spatial and temporal aggregated ABM outputs were in realistic ranges when compared to observed data. Our ABM hence represents a tool to assess the impact of the ever growing challenges to North Sea fisheries and provides insight into fisher behavior beyond profit maximization.

Peer reviewed Online Protest and Repression in Authoritarian Settings (OPRAS)
Nanda Wijermans Annie Waldherr Aytalina Kulichkina | Published Tuesday, January 27, 2026 | Last modified Tuesday, April 07, 2026This agent-based model, developed for the study “Online Protest and Repression in Authoritarian Settings,” examines how online protest and repression evolve in authoritarian contexts and how these dynamics affect ordinary users’ attitudes and behavior on social media. The model integrates key theoretical and empirical insights into social media use and core political factors that shape digital contention in authoritarian settings. The following questions are addressed: (1) how online protest–repression dynamics unfold across different levels of authoritarianism and varying compositions of committed accounts, and (2) how ordinary users’ internal propensity to protest and their perceived probability of successful repression change during online protest-repression contestation. The model is evaluated against two empirically grounded macro patterns observed in the real world. The first is enduring protest: online protest becomes dominant as vocal protesters grow to outnumber vocal repressors, shrinking the pool of silent users and stabilizing a pro-protest majority. The second is suppressed protest: online dissent is contained as vocal repression and silence expand in response to protest, yielding a sustained majority of repressive and silent accounts. Together, these dynamics demonstrate how dissenting voices are empowered and suppressed online in authoritarian settings.
Agent modeling (ABM) as a tool to improve the mobility of “avoidant” birds in an ecological corridor in the localities of Chapinero, Teusaquillo, Barrios Unidos and Engativá of Bogotá city
Paula Alejandra Meza Maria Angela Echeverry-Galvis Mauricio González Méndez | Published Wednesday, June 24, 2026The purpose of this model is to analyze different configurations and scenarios of ecological corridors to simulate the movement of three avoider bird species at a local scale: Chondrohierax uncinatus (Accipitridae), a large carnivorous bird; Ampelion rubrocristatus (Cotingidae), a species that seeks areas with substantial land cover for refuge and rest; and Coeligena bonapartei (Trochilidae), a large hummingbird that prefers areas with a rich and diverse food supply. The model focusses on juvenile bird individuals seeking refuge and food, taking into account the mobility parameters of each species and the existing land cover types within the study area.
Specifically, the model aims to:
• Simulate the movement of 45 avoiders birds which are considered umbrella species sensitive to urban changes (which were chosen based on their specific biological and ecological requirements and parameters relevant to urban conservation efforts), 15 avoiders birds per specie to cross a two-dimensional world predominant urban.
• To be able to select which corridor scenario would be the most beneficial, in order to help the mobility of other species affected by urban fragmentation.
• Contribute to urban ecology research and support decision-making processes by relevant stakeholders.
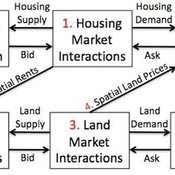
Coupled Housing and Land Markets (CHALMS)
Nicholas Magliocca Virginia Mcconnell Margaret Walls | Published Friday, November 02, 2012 | Last modified Monday, October 27, 2014CHALMS simulates housing and land market interactions between housing consumers, developers, and farmers in a growing ex-urban area.
Risks and Hedonics in Empirical Agent-based land market (RHEA) model
Tatiana Filatova Koen de Koning | Published Monday, April 01, 2019RHEA aims to provide a methodological platform to simulate the aggregated impact of households’ residential location choice and dynamic risk perceptions in response to flooding on urban land markets. It integrates adaptive behaviour into the spatial landscape using behavioural theories and empirical data sources. The platform can be used to assess: how changes in households’ preferences or risk perceptions capitalize in property values, how price dynamics in the housing market affect spatial demographics in hazard-prone urban areas, how structural non-marginal shifts in land markets emerge from the bottom up, and how economic land use systems react to climate change. RHEA allows direct modelling of interactions of many heterogeneous agents in a land market over a heterogeneous spatial landscape. As other ABMs of markets it helps to understand how aggregated patterns and economic indices result from many individual interactions of economic agents.
The model could be used by scientists to explore the impact of climate change and increased flood risk on urban resilience, and the effect of various behavioural assumptions on the choices that people make in response to flood risk. It can be used by policy-makers to explore the aggregated impact of climate adaptation policies aimed at minimizing flood damages and the social costs of flood risk.
A data-informed bounded-confidence opinion dynamics model
Bruce Edmonds | Published Wednesday, March 10, 2021The simulation is a variant of the “ToRealSim OD variants - base v2.7” base model, which is based on the standard DW opinion dynamics model (but with the differences that rather than one agent per tick randomly influencing another, all agents randomly influence one other per tick - this seems to make no difference to the outcomes other than to scale simulation time). Influence can be made one-way by turning off the two-way? switch
Various additional variations and sources of noise are possible to test robustness of outcomes to these (compared to DW model).
In this version agent opinions change following the empirical data collected in some experiments (Takács et al 2016).
Such an algorithm leaves no role for the uncertainties in other OD models. [Indeed the data from (Takács et al 2016) indicates that there can be influence even when opinion differences are large - which violates a core assumption of these]. However to allow better comparison with other such models there is a with-un? switch which allows uncertainties to come into play. If this is on, then influence (according to above algorithm) is only calculated if the opinion difference is less than the uncertainty. If an agent is influenced uncertainties are modified in the same way as standard DW models.
Peer reviewed Viable North Sea (ViNoS): A NetLogo Agent-based Model of German Small-scale Fisheries
Wolfgang Nikolaus Probst Jieun Seo Jürgen Scheffran Carsten Lemmen Sascha Hokamp Verena Mühlberger Serra Örey | Published Thursday, May 25, 2023 | Last modified Tuesday, December 05, 2023Viable North Sea (ViNoS) is an Agent-based Model of the German North Sea Small-scale Fisheries in a Social-Ecological Systems framework focussing on the adaptive behaviour of fishers facing regulatory, economic, and resource changes. Small-scale fisheries are an important part both of the cultural perception of the German North Sea coast and of its fishing industry. These fisheries are typically family-run operations that use smaller boats and traditional fishing methods to catch a variety of bottom-dwelling species, including plaice, sole, and brown shrimp. Fisheries in the North Sea face area competition with other uses of the sea – long practiced ones like shipping, gas exploration and sand extractions, and currently increasing ones like marine protection and offshore wind farming. German authorities have just released a new maritime spatial plan implementing the need for 30% of protection areas demanded by the United Nations High Seas Treaty and aiming at up to 70 GW of offshore wind power generation by 2045. Fisheries in the North Sea also have to adjust to the northward migration of their established resources following the climate heating of the water. And they have to re-evaluate their economic balance by figuring in the foreseeable rise in oil price and the need for re-investing into their aged fleet.
Displaying 10 of 195 results for "Ingo Kowarik" clear search