Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 142 results for "Andrew Nelson" clear search
Can ethnic tolerance curb self-reinforcing school segregation? A theoretical Agent Based Model
Lucas Sage Andreas Flache | Published Monday, August 10, 2020Schelling and Sakoda prominently proposed computational models suggesting that strong ethnic residential segregation can be the unintended outcome of a self-reinforcing dynamic driven by choices of individuals with rather tolerant ethnic preferences. There are only few attempts to apply this view to school choice, another important arena in which ethnic segregation occurs. In the current paper, we explore with an agent-based theoretical model similar to those proposed for residential segregation, how ethnic tolerance among parents can affect the level of school segregation. More specifically, we ask whether and under which conditions school segregation could be reduced if more parents hold tolerant ethnic preferences. We move beyond earlier models of school segregation in three ways. First, we model individual school choices using a random utility discrete choice approach. Second, we vary the pattern of ethnic segregation in the residential context of school choices systematically, comparing residential maps in which segregation is unrelated to parents’ level of tolerance to residential maps reflecting their ethnic preferences. Third, we introduce heterogeneity in tolerance levels among parents belonging to the same group. Our simulation experiments suggest that ethnic school segregation can be a very robust phenomenon, occurring even when about half of the population prefers mixed to segregated schools. However, we also identify a “sweet spot” in the parameter space in which a larger proportion of tolerant parents makes the biggest difference. This is the case when parents have moderate preferences for nearby schools and there is only little residential segregation. Further experiments are presented that unravel the underlying mechanisms.
Simulation of the Governance of Complex Systems
Fabian Adelt Johannes Weyer Robin D Fink Andreas Ihrig | Published Monday, December 18, 2017 | Last modified Friday, March 02, 2018Simulation-Framework to study the governance of complex, network-like sociotechnical systems by means of ABM. Agents’ behaviour is based on a sociological model of action. A set of basic governance mechanisms helps to conduct first experiments.
A model to explore the link between the gender-gap reversal in education and relative divorce risks
Jan Van Bavel Christine Schnor André Grow | Published Thursday, June 30, 2016 | Last modified Wednesday, September 13, 2017This model explores a social mechanism that links the reversal of the gender gap in education with changing patterns in relative divorce risks in 12 European countries.

MEGADAPT - Socio-hydrological risk model - Theoretical (no data) implementation
Marco Janssen Andres Baeza-Castro Luis Bojorquez Hallie Eakin | Published Wednesday, February 06, 2019The model simulates the decisions of residents and a water authority to respond to socio-hydrological hazards. Residents from neighborhoods are located in a landscape with topographic complexity and two problems: water scarcity in the peripheral neighborhoods at high altitude and high risk of flooding in the lowlands, at the core of the city. The role of the water authority is to decide where investments in infrastructure should be allocated to reduce the risk to water scarcity and flooding events in the city, and these decisions are made via a multi-objective site selection procedure. This procedure accounts for the interdependencies and feedback between the urban landscape and a policy scenario that defines the importance, or priorities, that the authority places on four criteria.
Neighborhoods respond to the water authority decisions by protesting against the lack of investment and the level of exposure to water scarcity and flooding. Protests thus simulate a form of feedback between local-level outcomes (flooding and water scarcity) and higher-level decision-making. Neighborhoods at high altitude are more likely to be exposed to water scarcity and lack infrastructure, whereas neighborhoods in the lowlands tend to suffer from recurrent flooding. The frequency of flooding is also a function of spatially uniform rainfall events. Likewise, neighborhoods at the periphery of the urban landscape lack infrastructure and suffer from chronic risk of water scarcity.
The model simulates the coupling between the decision-making processes of institutional actors, socio-political processes and infrastructure-related hazards. In the documentation, we describe details of the implementation in NetLogo, the description of the procedures, scheduling, and the initial conditions of the landscape and the neighborhoods.
This work was supported by the National Science Foundation under Grant No. 1414052, CNH: The Dynamics of Multi-Scalar Adaptation in Megacities (PI Hallie Eakin).
CINCH1 (Covid-19 INfection Control in Hospitals)
Nick Gotts | Published Sunday, August 29, 2021CINCH1 (Covid-19 INfection Control in Hospitals), is a prototype model of physical distancing for infection control among staff in University College London Hospital during the Covid-19 pandemic, developed at the University of Leeds, School of Geography. It models the movement of collections of agents in simple spaces under conflicting motivations of reaching their destination, maintaining physical distance from each other, and walking together with a companion. The model incorporates aspects of the Capability, Opportunity and Motivation of Behaviour (COM-B) Behaviour Change Framework developed at University College London Centre for Behaviour Change, and is aimed at informing decisions about behavioural interventions in hospital and other workplace settings during this and possible future outbreaks of highly contagious diseases. CINCH1 was developed as part of the SAFER (SARS-CoV-2 Acquisition in Frontline Health Care Workers – Evaluation to Inform Response) project
(https://www.ucl.ac.uk/behaviour-change/research/safer-sars-cov-2-acquisition-frontline-health-care-workers-evaluation-inform-response), funded by the UK Medical Research Council. It is written in Python 3.8, and built upon Mesa version 0.8.7 (copyright 2020 Project Mesa Team).
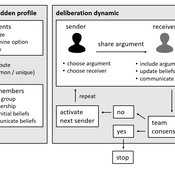
Agent-based model of team decision-making in hidden profile situations
Andreas Flache Jonas Stein Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
Benchmark for RepastHPC Agent-based modeling and simulation (ABMS) platform
Andreu Moreno Vendrell Josep Jorba Eduardo César Anna Sikora | Published Friday, November 22, 2024Agent-based modeling and simulation (ABMS) is a class of computational models for simulating the actions and interactions of autonomous agents with the goal of assessing their effects on a system as a whole. Several frameworks for generating parallel ABMS applications have been developed taking advantage of their common characteristics, but there is a lack of a general benchmark for comparing the performance of generated applications. We propose and design a benchmark that takes into consideration the most common characteristics of this type of applications and includes parameters for influencing their relevant performance aspects. We provide an initial implementation of the benchmark for RepastHPC one of the most popular parallel ABMS platforms, and we use it for comparing the applications generated by these platforms.
Benchmark for FLAME Agent-based modeling and simulation (ABMS) platform
Andreu Moreno Vendrell Josep Jorba Eduardo César Anna Sikora | Published Friday, November 22, 2024Agent-based modeling and simulation (ABMS) is a class of computational models for simulating the actions and interactions of autonomous agents with the goal of assessing their effects on a system as a whole. Several frameworks for generating parallel ABMS applications have been developed taking advantage of their common characteristics, but there is a lack of a general benchmark for comparing the performance of generated applications. We propose and design a benchmark that takes into consideration the most common characteristics of this type of applications and includes parameters for influencing their relevant performance aspects. We provide an initial implementation of the benchmark for FLAME one of the most popular parallel ABMS platforms, and we use it for comparing the applications generated by these platforms.
Contact Tracing agent model
Andreu Moreno Vendrell Josep Jorba Eduardo César Anna Sikora | Published Friday, November 22, 2024Contact Tracing Repast HPC agent model
Peer reviewed SWIRS Spread of a woody invader in riparian systems
Moira Zellner Beatriz Sosa Carlos Andrés Chiale | Published Tuesday, May 09, 2023Riparian forests are one of the most vulnerable ecosystems to the development of biological invasions, therefore limiting their spread is one of the main challenges for conservation. The main factors that explain plant invasions in these ecosystems are the capacity for both short- and long-distance seed dispersion, and the occurrence of suitable habitats that facilitate the establishment of the invasive species. Large floods constitute an abiotic filter for invasion.
This model simulates the spatio-temporal spread of the woody invader Gleditsia. triacanthos in the riparian forest of the National Park Esteros de Farrapos e Islas del Río Uruguay, a riparian system in the coast of the Uruguay river (South America). In this model, we represent different environmental conditions for the development of G. triacanthos, long- and short-distance spread of its fruits, and large floods as the main factor of mortality for fruit and early stages.
Field results show that the distribution pattern of this invasive species is limited by establishment, i.e. it spreads locally through the expansion of small areas, and remotely through new invasion foci. This model recreates this dispersion pattern. We use this model to derive management implications to control the spread of G. triacanthos
Displaying 10 of 142 results for "Andrew Nelson" clear search