Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 140 results for "Greg R Madey" clear search

Peer reviewed HUMLAND: HUMan impact on LANDscapes agent-based model
Fulco Scherjon Anastasia Nikulina Anhelina Zapolska Maria Antonia Serge Marco Davoli Dave van Wees Katharine MacDonald | Published Monday, October 16, 2023The HUMan impact on LANDscapes (HUMLAND) model has been developed to track and quantify the intensity of different impacts on landscapes at the continental level. This agent-based model focuses on determining the most influential factors in the transformation of interglacial vegetation with a specific emphasis on burning organized by hunter-gatherers. HUMLAND integrates various spatial datasets as input and target for the agent-based model results. Additionally, the simulation incorporates recently obtained continental-scale estimations of fire return intervals and the speed of vegetation regrowth. The obtained results include maps of possible scenarios of modified landscapes in the past and quantification of the impact of each agent, including climate, humans, megafauna, and natural fires.
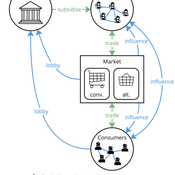
Agent-based model of power dynamics in agri-food systems
Tim Williams | Published Sunday, October 27, 2024 | Last modified Thursday, June 12, 2025This is a stylised agent-based model designed to explore the conditions that lead to lock-ins and transitions in agri-food systems.
The model represents interactions between four different types of agents: farmers, consumers, markets, and the state. Farmers and consumers are heterogeneous, and at each time step decide whether to trade with one of two market agents: the conventional or alternative. The state agent provides subsidies to the farmers at each time step.
The key emergent outcome is the fraction of trade in each time step that flows through the alternative market agent. This arises from the distributed decisions of farmer and consumer agents. A “sustainability transition” is defined as a shift in the dominant practices (and associated balance of power) towards the alternative paradigm.
…

Harvesting daisies in Daisyworld
Marco Janssen | Published Saturday, July 22, 2017Comparing impact of alternative behavioral theories in a simple social-ecological system.
Formal Organization Hierarchy and Informal Networks - "The Company Behind the Org Chart"
Tom Briggs | Published Sunday, April 18, 2021A generalized organizational agent- based model (ABM) containing both formal organizational hierarchy and informal social networks simulates organizational processes that occur over both formal network ties and informal networks.
Peer reviewed Coupled demographic dynamics of herd and household in pastoral systems
Mark Moritz Ian M Hamilton Andrew Yoak Abigail Buffington Chelsea E Hunter Daniel C Peart | Published Saturday, April 08, 2023This purpose of this model is to understand how the coupled demographic dynamics of herds and households constrain the growth of livestock populations in pastoral systems.
The Effect of Different Governmental Pandemic Control Measures on the Spread of a Virus Disease
Chiara Letter | Published Wednesday, January 26, 2022In this model, the spread of a virus disease in a network consisting of school pupils, employed, and umemployed people is simulated. The special feature in this model is the distinction between different types of links: family-, friends-, school-, or work-links. In this way, different governmental measures can be implemented in order to decelerate or stop the transmission.
Success bias imitation increases the probability of effectively dealing with ecological disturbances
Jacopo A. Baggio Vicken Hillis | Published Thursday, April 13, 2017 | Last modified Thursday, August 02, 2018This model aims to investigate how different type of learning (social system) and disturbance specific attributes (ecological system) influence adoption of treatment strategies to treat the effects of ecological disturbances.
THE STATUS ARENA
Gert Jan Hofstede Jillian Student Mark R Kramer | Published Wednesday, June 08, 2016 | Last modified Tuesday, January 09, 2018Status-power dynamics on a playground, resulting in a status landscape with a gender status gap. Causal: individual (beauty, kindness, power), binary (rough-and-tumble; has-been-nice) or prior popularity (status). Cultural: acceptability of fighting.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
MayaSim: An agent-based model of the ancient Maya social-ecological system
Scott Heckbert | Published Wednesday, July 11, 2012 | Last modified Tuesday, July 02, 2013MayaSim is an agent-based, cellular automata and network model of the ancient Maya. Biophysical and anthropogenic processes interact to grow a complex social ecological system.
Displaying 10 of 140 results for "Greg R Madey" clear search