Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 156 results strategies clear search
Individual-based modelling as a tool for elephant poaching mitigation
Ernesto Carrella Richard Bailey Emily Neil Jens Koed Madsen Nicolas Payette | Published Tuesday, June 18, 2019 | Last modified Thursday, August 01, 2019We develop an IBM that predicts how interactions between elephants, poachers, and law enforcement affect poaching levels within a virtual protected area. The model is theoretical at this stage and is not meant to provide a realistic depiction of poaching, but instead to demonstrate how IBMs can expand upon the existing modelling work done in this field, and to provide a framework for future research. The model could be further developed into a useful management support tool to predict the outcomes of various poaching mitigation strategies at real-world locations. The model was implemented in NetLogo version 6.1.0.
We first compared a scenario in which poachers have prescribed, non-adaptive decision-making and move randomly across the landscape, to one in which poachers adaptively respond to their memories of elephant locations and where other poachers have been caught by law enforcement. We then compare a situation in which ranger effort is distributed unevenly across the protected area to one in which rangers patrol by adaptively following elephant matriarchal herds.

Peer reviewed Organizational behavior in the hierarchy model
Smarzhevskiy Ivan | Published Tuesday, June 18, 2019 | Last modified Wednesday, July 31, 2019In a two-level hierarchical structure (consisting of the positions of managers and operators), persons holding these positions have a certain performance and the value of their own (personal perception in this, simplified, version of the model) perception of each other. The value of the perception of each other by agents is defined as a random variable that has a normal distribution (distribution parameters are set by the control elements of the interface).
In the world of the model, which is the space of perceptions, agents implement two strategies: rapprochement with agents that perceive positively and distance from agents that perceive negatively (both can be implemented, one of these strategies, or neither, the other strategy, which makes the agent stationary). Strategies are implemented in relation to those agents that are in the radius of perception (PerRadius).
The manager (Head) forms a team of agents. The performance of the group (the sum of the individual productivities of subordinates, weighted by the distance from the leader) varies depending on the position of the agents in space and the values of their individual productivities. Individual productivities, in the current version of the model, are set as a random variable distributed evenly on a numerical segment from 0 to 100. The manager forms the team 1) from agents that are in (organizational) radius (Op_Radius), 2) among agents that the manager perceives positively and / or negatively (both can be implemented, one of the specified rules, or neither, which means the refusal of the command formation).
Agents can (with a certain probability, given by the variable PrbltyOfDecisn%), in case of a negative perception of the manager, leave his group permanently.
It is possible in the model to change on the fly radii values, update the perception value across the entire population and the perception of an individual agent by its neighbors within the perception radius, and the probability values for a subordinate to make a decision about leaving the group.
You can also change the set of strategies for moving agents and strategies for recruiting a team manager. It is possible to add a randomness factor to the movement of agents (Stoch_Motion_Speed, the default is set to 0, that is, there are no random movements).
…

Opportunity cost of walking away in the spatial iterated prisoner's dilemma
Luke Premo | Published Wednesday, April 03, 2019Previous work with the spatial iterated prisoner’s dilemma has shown that “walk away” cooperators are able to outcompete defectors as well as cooperators that do not respond to defection, but it remains to be seen just how robust the so-called walk away strategy is to ecologically important variables such as population density, error, and offspring dispersal. Our simulation experiments identify socio-ecological conditions in which natural selection favors strategies that emphasize forgiveness over flight in the spatial iterated prisoner’s dilemma. Our interesting results are best explained by considering how population density, error, and offspring dispersal affect the opportunity cost associated with walking away from an error-prone partner.
Peer reviewed From Individual Fuzzy Cognitive Maps to Agent Based Models: Modeling Multi-Factorial and Multi-stakeholder Decision-Making for Water Scarcity
Sara Mehryar | Published Monday, March 04, 2019 | Last modified Wednesday, August 28, 2019This model simulates different farmers’ decisions and actions to adapt to the water scarce situation. This simulation helps to investigate how farmers’ strategies may impact macro-behavior of the social-ecological system i.e. overall groundwater use change and emigration of farmers. The environmental variables’ behavior and behavioral rules of stakeholders are captured with Fuzzy Cognitive Map (FCM) that is developed with both qualitative and quantitative data, i.e. stakeholders’ knowledge and empirical data from studies. This model have been used to compare the impact of different water scarcity policies on overall groundwater use in a farming community facing water scarcity.
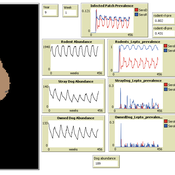
Peer reviewed MHMSLeptoDy (Multi-host, multi-serovar Leptospira Dynamics Model)
Aniruddha Belsare Matthew Gompper Meghan Mason Claudia Munoz-Zanzi | Published Tuesday, January 29, 2019 | Last modified Tuesday, March 12, 2019Leptospirosis is a neglected, bacterial zoonosis with worldwide distribution, primarily a disease of poverty. More than 200 pathogenic serovars of Leptospira bacteria exist, and a variety of species may act as reservoirs for these serovars. Human infection is the result of direct or indirect contact with Leptospira bacteria in the urine of infected animal hosts, primarily livestock, dogs, and rodents. There is increasing evidence that dogs and dog-adapted serovar Canicola play an important role in the burden of leptospirosis in humans in marginalized urban communities. What is needed is a more thorough understanding of the transmission dynamics of Leptospira in these marginalized urban communities, specifically the relative importance of dogs and rodents in the transmission of Leptospira to humans. This understanding will be vital for identifying meaningful intervention strategies.
One of the main objectives of MHMSLeptoDy is to elucidate transmission dynamics of host-adapted Leptospira strains in multi-host system. The model can also be used to evaluate alternate interventions aimed at reducing human infection risk in small-scale communities like urban slums.
The Evolution of Tribalism: A Social-Ecological Model of Cooperation and Inter-group Conflict Under Pastoralism
Nicholas Seltzer | Published Monday, January 21, 2019This study investigates a possible nexus between inter-group competition and intra-group cooperation, which may be called “tribalism.” Building upon previous studies demonstrating a relationship between the environment and social relations, the present research incorporates a social-ecological model as a mediating factor connecting both individuals and communities to the environment. Cyclical and non-cyclical fluctuation in a simple, two-resource ecology drive agents to adopt either “go-it-alone” or group-based survival strategies via evolutionary selection. Novelly, this simulation employs a multilevel selection model allowing group-level dynamics to exert downward selective pressures on individuals’ propensity to cooperate within groups. Results suggest that cooperation and inter-group conflict are co-evolved in a triadic relationship with the environment. Resource scarcity increases inter-group competition, especially when resources are clustered as opposed to widely distributed. Moreover, the tactical advantage of cooperation in the securing of clustered resources enhanced selective pressure on cooperation, even if that implies increased individual mortality for the most altruistic warriors. Troubling, these results suggest that extreme weather, possibly as a result of climate change, could exacerbate conflict in sensitive, weather-dependent social-ecologies—especially places like the Horn of Africa where ecologically sensitive economic modalities overlap with high-levels of diversity and the wide-availability of small arms. As well, global development and foreign aid strategists should consider how plans may increase the value of particular locations where community resources are built or aid is distributed, potentially instigating tribal conflict. In sum, these factors, interacting with pre-existing social dynamics dynamics, may heighten inter-ethnic or tribal conflict in pluralistic but otherwise peaceful communities.
For special issue submission in JASSS.
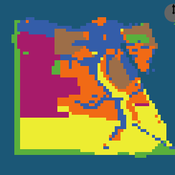
Peer reviewed ELTAP-Egy model (Energy Landscape Transition Analysis and Planning in Egypt)
Mostafa Shaaban Jürgen Scheffran Jürgen Böhner Mohamed Salah Elsobki | Published Saturday, December 29, 2018The model investigates conditions, scenarios and strategies for future planning of energy in Egypt, with an emphasis on alternative energy pathways and a sustainable electricity supply mix as part of an energy roadmap till the year 2100. It combines the multi-criteria decision analysis (MCDA) with agent-based modeling (ABM) and Geographic Information Systems (GIS) visualization to integrate the interactions of the decisions of multi-agents, the multi-criteria evaluation of sustainability, the time factor and the site factors to assess the transformation of energy landscapes.
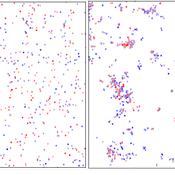
Evolutionary Prosocial Behavior Algorithm 1.1 (EPBA_1.1)
Andrea Ceschi | Published Tuesday, September 04, 2018In order to test how prosocial strategies (compassionate altruism vs. reciprocity) grow over time, we developed an evolutionary simulation model where artificial agents are equipped with different emotionally-based drivers that vary in strength. Evolutionary algorithms mimic the evolutionary selection process by letting the chances of agents conceiving offspring depend on their fitness. Equipping the agents with heritable prosocial strategies allows for a selection of those strategies that result in the highest fitness. Since some prosocial attributes may be more successful than others, an initially heterogeneous population can specialize towards altruism or reciprocity. The success of particular prosocial strategies is also expected to depend on the cultural norms and environmental conditions the agents live in.
How does knowledge infrastructure mobilization influence the safe operating space of regulated exploited ecosystems?
Jean-Denis Mathias | Published Tuesday, July 17, 2018Decision-makers often have to act before critical times to avoid the collapse of ecosystems using knowledge \textcolor{red}{that can be incomplete or biased}. Adaptive management may help managers tackle such issues. However, because the knowledge infrastructure required for adaptive management may be mobilized in several ways, we study the quality and the quantity of knowledge provided by this knowledge infrastructure. In order to analyze the influence of mobilized knowledge, we study how the following typology of knowledge and its use may impact the safe operating space of exploited ecosystems: 1) knowledge of the past based on a time series distorted by measurement errors; 2) knowledge of the current systems’ dynamics based on the representativeness of the decision-makers’ mental models of the exploited ecosystem; 3) knowledge of future events based on decision-makers’ likelihood estimates of extreme events based on modeling infrastructure (models and experts to interpret them) they have at their disposal. We consider different adaptive management strategies of a general regulated exploited ecosystem model and we characterize the robustness of these strategies to biased knowledge. Our results show that even with significant mobilized knowledge and optimal strategies, imperfect knowledge may still shrink the safe operating space of the system leading to the collapse of the system. However, and perhaps more interestingly, we also show that in some cases imperfect knowledge may unexpectedly increase the safe operating space by suggesting cautious strategies.
The code enables to calculate the safe operating spaces of different managers in the case of biased and unbiased knowledge.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
Displaying 10 of 156 results strategies clear search