Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 127 results for "Nathan Ryan" clear search
Peer reviewed STiMUS: A Stigmergic–Mutualistic Agent-Based Model of Teamwork on Shared Digital Artefacts (IMOI)
Yevgeny Patarakin | Published Friday, July 03, 2026 | Last modified Wednesday, July 22, 2026STiMUS (Stigmergic–Mutualistic IMOI Model) is an agent-based model of teamwork in socio-technical systems where contributors collaborate through shared digital artefacts — wiki pages, code files, issue tickets, project cards, Scratch projects — represented as patches in a NetLogo world. The model integrates two coordination mechanisms. Stigmergy is indirect coordination through traces left in a shared environment: each edit deposits a pheromone that diffuses to neighbouring patches and evaporates over time, so recent activity attracts further contributions. Mutualism is a reciprocal benefit loop in which valuable, well-maintained artefacts raise contributor motivation and shared understanding, while motivated contributors improve artefacts.
Contributors (turtles of the contributor breed) carry individual state: skill, motivation, shared-mental-model, specialty, benefit-gain, and an explicit-mode flag. At each tick every contributor selects a target artefact with an ant-colony-optimization-style rule weighing the artefact’s pheromone, incompleteness (1 - completeness), resource-value, and topic match between specialty and the artefact’s topic-tag; with probability p-explicit it instead takes the patch with the highest maintenance-need, modelling explicit task assignment. Each edit increases pheromone, quality, completeness and reuse-count, raises resource-value, lowers maintenance-need, and appends the editor to the artefact’s edit-authors list. When the previous last-editor-id differs from the current editor, the Edit Succession Ratio rises, the editor’s shared-mental-model grows, and a co-editing link is created — operationalising the idea that repeated cross-author succession on the same artefact builds shared understanding. Contributors’ motivation is updated from the benefit drawn from the visited artefact.
Each patch maintains a stigmergic layer (pheromone, quality, completeness, recentness, last-editor-id, edit-count, edit-authors) and a mutualistic layer (resource-value, reuse-count, maintenance-need, topic-tag), plus task flags (is-task?, task-complexity). Global monitors report the Edit Succession Ratio (ESR = cross-author-edits / total-edits, and an alternative esr-value = share of edited patches with more than one distinct author), mean-quality, mean-resource-value, a mutualism-index averaging contributor benefit and resource value, coediting-density (network density of the co-editing graph), active-pages-share, and task-completion-rate. The model logs every edit as a bipartite edge (tick, author_id, pageid, specialty, topic_tag, quality), exportable to CSV.
…
SONG - Simulation of Network Growth
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013SONG is a simulator designed for simulating the process of transportation network growth.
Human Environment Estuarine Systems Investigator
Andrew Allison | Published Friday, February 26, 2021This model simulates the form and function of an idealised estuary with associated barrier-spit complex on the north east coast of New Zealand’s North Island (from Bream Bay to central Bay of Plenty) during the years 2010 - 2050 CE. It combines variables from social, ecological and geomorphic systems to simulate potential directions of change in shallow coastal systems in response to external forcing from land use, climate, pollution, population density, demographics, values and beliefs. The estuary is over 1000Ha, making it a large estuary according to Hume et al. (2007) - there are 12 large estuaries in the Auckland region alone (Suyadi et al., 2019). The model was developed as part of Andrew Allison’s PhD Thesis in Geography from the School of Environment and Institute of Marine Science, University of Auckland, New Zealand. The model setup allows for alteration of geomorphic, ecological and social variables to suit the specific conditions found in various estuaries along the north east coast of New Zealand’s North Island.
This model is not a predictive or forecasting model. It is designed to investigate potential directions of change in complex shallow coastal systems. This model must not be used for any purpose other than as a heuristic to facilitate researcher and stakeholder learning and for developing system understanding (as per Allison et al., 2018).
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700
Asymmetric Demographic Hysteresis in a Spatial Agent-Based Urban System
Chen Shen | Published Friday, July 24, 2026This paper develops a spatial agent-based model to examine how fertility regime shifts reshape population concentration and wealth distribution in an abstract urban system. Migration decisions combine population preference, cultural homophily, expected net income, and resource endowment through a standardised softmax utility. The design is deliberately stylised: it is not calibrated to a particular country or city system, but is intended to isolate the feedbacks linking migration, fertility, urban scaling, and accumulated wealth.
The simulations reveal robust directional asymmetry. When fertility shifts from low to high, population concentration responds rapidly; when fertility shifts from high to low, concentration declines only after a detectable delay and may temporarily continue in the previous direction. Wealth adds a second layer of hysteresis: cell total-wealth concentration follows population concentration with delay, cell mean-wealth inequality and system-level wealth indicators are slower still, and phase-space trajectories form loops rather than collapsing onto a single population–wealth curve. Robustness experiments indicate that longer fertility cycles, wider mobility neighbourhoods, and smoother resource landscapes change the magnitude of delay and overshoot, but do not remove the qualitative asymmetry. The paper argues that demographic decline should be understood not as the mirror image of demographic expansion, but as a path-dependent transition mediated by fast migration-income feedbacks and slower fertility, cohort, culture, and wealth mechanisms.

Soil microbe-predator model with enzymes
Randall Boone John C Moore Akihiro Koyama Kirstin Holfelder | Published Thursday, November 21, 2013We seek to improve understanding of roles enzyme play in soil food webs. We created an agent-based simulation of a simple food web that includes enzymatic activity. The model was used in a publication, Moore et al. (in press; Biochemistry).
A simplified Arthur & Polak logic circuit model of combinatory technology build-out via incremental development. Only some inventions trigger radical effects, suggesting they depend on whole interdependent systems rather than specific innovations.
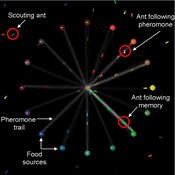
Composite Collective Decision Making - ant colony foraging model
Tomer Czaczkes Benjamin I Czaczkes | Published Thursday, December 17, 2015The model explores how two types of information - social (in the form of pheromone trails) and private (in the form of route memories) affect ant colony level foraging in a variable enviroment.
Informal risk-sharing cooperatives : ORP and Learning
Juliette Rouchier Victorien Barbet Renaud Bourlès | Published Monday, February 13, 2017 | Last modified Tuesday, May 16, 2023The model studies the dynamics of risk-sharing cooperatives among heterogeneous farmers. Based on their knowledge on their risk exposure and the performance of the cooperative farmers choose whether or not to remain in the risk-sharing agreement.
Displaying 10 of 127 results for "Nathan Ryan" clear search