Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 142 results for "Andrew Nelson" clear search
Schelling Model of the City of Salzburg
Andreas Schlagbauer | Published Monday, December 05, 2022The purpose of the model is to better understand, how different factors for human residential choices affect the city’s segregation pattern. Therefore, a Schelling (1971) model was extended to include ethnicity, income, and affordability and applied to the city of Salzburg. So far, only a few studies have tried to explore the effect of multiple factors on the residential pattern (Sahasranaman & Jensen, 2016, 2018; Yin, 2009). Thereby, models using multiple factors can produce more realistic results (Benenson et al., 2002). This model and the corresponding thesis aim to fill that gap.
Friendship Games Rev 1.0
David Dixon | Published Friday, October 07, 2011 | Last modified Saturday, April 27, 2013A friendship game is a kind of network game: a game theory model on a network. This is a NetLogo model of an agent-based adaptation of “‘Friendship-based’ Games” by PJ Lamberson. The agents reach an equilibrium that depends on the strategy played and the topology of the network.
Asymmetric two-sided matching
Naoki Shiba | Published Wednesday, January 09, 2013 | Last modified Tuesday, May 28, 2013This model is an extended version of the matching problem including the mate search problem, which is the generalization of a traditional optimization problem. The matching problem is extended to a form of asymmetric two-sided matching problem.
Parental choices, children's skills, and skill inequality: An agent-based model implemented in Python
Andrés Cardona | Published Thursday, October 30, 2014The model explores the emergence of inequality in cognitive and socio-emotional skills at the societal level within and across generations that results from differences in parental investment behavior during childhood and adolescence.
PopComp
Andre Costopoulos | Published Thursday, December 10, 2020PopComp by Andre Costopoulos 2020
andre.costopoulos@ualberta.ca
Licence: DWYWWI (Do whatever you want with it)
I use Netlogo to build a simple environmental change and population expansion and diffusion model. Patches have a carrying capacity and can host two kinds of populations (APop and BPop). Each time step, the carrying capacity of each patch has a given probability of increasing or decreasing up to a maximum proportion.
…
NDiv
Andre Costopoulos | Published Tuesday, April 10, 2018 | Last modified Monday, April 30, 2018Code for my SAA2018 Presentation
PluchinoEtAl_ExtendedByAC
Andre Costopoulos | Published Tuesday, September 03, 2019 | Last modified Friday, January 31, 2020Extension of Pluchino et al.’s 2018 success vs talent model, to allow talented individuals to mitigate unlucky events.
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.
Peer reviewed Horse population dynamics
Nika Galic | Published Tuesday, November 12, 2013 | Last modified Wednesday, October 29, 2014This model investigates the link between prescribed growth in body size, population dynamics and density dependence through population feedback on available resources.
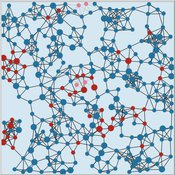
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
Displaying 10 of 142 results for "Andrew Nelson" clear search