Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 97 results resources clear search
Network structures tutorial
Tom Brughmans | Published Sunday, September 30, 2018 | Last modified Tuesday, October 02, 2018A draft model with some useful code for creating different network structures using the Netlogo NW extension. This model is used for the following tutorial:
Brughmans, T. (2018). Network structures and assembling code in Netlogo, Tutorial, https://archaeologicalnetworks.wordpress.com/resources/#structures .
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
Peer Review Game
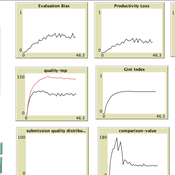
Giangiacomo Bravo Flaminio Squazzoni Francisco Grimaldo Federico Bianchi | Published Monday, April 30, 2018NetLogo software for the Peer Review Game model. It represents a population of scientists endowed with a proportion of a fixed pool of resources. At each step scientists decide how to allocate their resources between submitting manuscripts and reviewing others’ submissions. Quality of submissions and reviews depend on the amount of allocated resources and biased perception of submissions’ quality. Scientists can behave according to different allocation strategies by simply reacting to the outcome of their previous submission process or comparing their outcome with published papers’ quality. Overall bias of selected submissions and quality of published papers are computed at each step.
Lakeland 2 is a simple version of the original Lakeland of Jager et al. (2000) Ecological Economics 35(3): 357-380. The model can be used to explore the consequences of different behavioral assumptions on resource and social dynamics.

Team Problem Solving and Motivation under Disorganization
Dinuka Herath | Published Sunday, August 13, 2017The model combines the two elements of disorganization and motivation to explore their impact on teams. Effects of disorganization on team task performance (problem solving)
05 CmLab V1.17 – Conservation of Money Laboratory
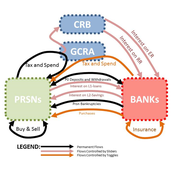
Garvin Boyle | Published Saturday, April 15, 2017In CmLab we explore the implications of the phenomenon of Conservation of Money in a modern economy. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
LBD Model: Learning-by-doing for sustainable management of renewable resources
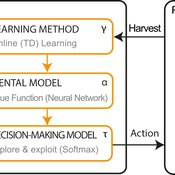
Emilie Lindkvist Örjan Ekeberg Jon Norberg | Published Thursday, March 09, 2017This is a simulation model of an intelligent agent that has the objective to learn sustainable management of a renewable resource, such as a fish stock.

Resource distribution effects on optimal foraging theory
Marco Janssen Kim Hill | Published Friday, January 27, 2017The original Ache model is used to explore different distributions of resources on the landscape and it’s effect on optimal strategies of the camps on hunting and camp movement.
An agent-based approach to weighted decision making in the spatially and temporally variable South African Paleoscape
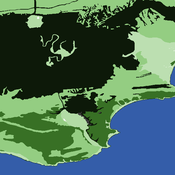
Colin Wren | Published Thursday, December 29, 2016This model simulates a foraging system based on Middle Stone Age plant and shellfish foraging in South Africa.
Cooperation Under Resources Pressure (CURP)
María Pereda José Manuel Galán Ordax José Santos | Published Monday, November 21, 2016 | Last modified Wednesday, April 25, 2018This is an agent-based model designed to explore the evolution of cooperation under changes in resources availability for a given population
Displaying 10 of 97 results resources clear search