Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 136 results for "Emily S Ihara" clear search
Knowledge Sharing in a Hospital
bpint Emily Molfino Joshua Goldstein Kathryn Schaefer Ziemer Mark Orr Bryan Lewis Jose Jimenez | Published Friday, January 27, 2023Organizations are complex systems comprised of many dynamic and evolving interaction patterns among individuals and groups. Understanding these interactions and how patterns, such as informal structures and knowledge sharing behavior, emerge are crucial to creating effective and efficient organizations. To explore such organizational dynamics, the agent-based model integrates a cognitive model, dynamic social networks, and a physical environment.
Demographic microsimulation for individuals and couples
Sabine Zinn | Published Wednesday, January 14, 2015The simulation model conducts fine-grained population projection by specifying life course dynamics of individuals and couples by means of traditional demographic microsimulation and by using agent-based modeling for mate matching.
Peer reviewed Viable North Sea (ViNoS): A NetLogo Agent-based Model of German Small-scale Fisheries
Wolfgang Nikolaus Probst Jieun Seo Jürgen Scheffran Carsten Lemmen Sascha Hokamp Verena Mühlberger Serra Örey | Published Thursday, May 25, 2023 | Last modified Tuesday, December 05, 2023Viable North Sea (ViNoS) is an Agent-based Model of the German North Sea Small-scale Fisheries in a Social-Ecological Systems framework focussing on the adaptive behaviour of fishers facing regulatory, economic, and resource changes. Small-scale fisheries are an important part both of the cultural perception of the German North Sea coast and of its fishing industry. These fisheries are typically family-run operations that use smaller boats and traditional fishing methods to catch a variety of bottom-dwelling species, including plaice, sole, and brown shrimp. Fisheries in the North Sea face area competition with other uses of the sea – long practiced ones like shipping, gas exploration and sand extractions, and currently increasing ones like marine protection and offshore wind farming. German authorities have just released a new maritime spatial plan implementing the need for 30% of protection areas demanded by the United Nations High Seas Treaty and aiming at up to 70 GW of offshore wind power generation by 2045. Fisheries in the North Sea also have to adjust to the northward migration of their established resources following the climate heating of the water. And they have to re-evaluate their economic balance by figuring in the foreseeable rise in oil price and the need for re-investing into their aged fleet.
Geospatial Agent-Based Model of Immigrant Settlement Dynamics in Metro Vancouver
Liliana Perez Navid Mahdizadeh Gharakhanlou Maryam Yousefi | Published Wednesday, December 03, 2025This agent-based model simulates how new immigrant households choose where to live in Metro Vancouver under the origins diversity scenario. The model begins with 16,000 household agents, reflecting an expected annual population increase of about 42,500 people based on an average household size of 2.56. Each agent is assigned four characteristics: one of ten origin categories, income level (adjusted using NOC data and recent immigrant earnings), likelihood of having children, and preferred mode of commuting. The ten origin groups are drawn from Census patterns, including six subgroups within the broader Asian category (China, India, the Philippines, Iran, South Korea, and Other Asian countries) and two categories for immigrants from the Americas. This refined classification better captures the diversity of newcomers arriving in the region.
MayaSim: An agent-based model of the ancient Maya social-ecological system
Scott Heckbert | Published Wednesday, July 11, 2012 | Last modified Tuesday, July 02, 2013MayaSim is an agent-based, cellular automata and network model of the ancient Maya. Biophysical and anthropogenic processes interact to grow a complex social ecological system.
Modeling information Asymmetries in Tourism
Jacopo A. Baggio Rodolfo Baggio | Published Monday, January 09, 2012 | Last modified Saturday, April 27, 2013A very simple model elaborated to explore what may happens when buyers (travelers) have more information than sellers (tourist destinations)
The PRIF Model
Davide Secchi | Published Friday, November 08, 2019This model takes into consideration Peer Reviewing under the influence of Impact Factor (PRIF) and it has the purpose to explore whether the infamous metric affects assessment of papers under review. The idea is to consider to types of reviewers, those who are agnostic towards IF (IU1) and those that believe that it is a measure of journal (and article) quality (IU2). This perception is somehow reflected in the evaluation, because the perceived scientific value of a paper becomes a function of the journal in which an article has been submitted. Various mechanisms to update reviewer preferences are also implemented.
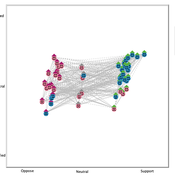
Gaming Polarisation: Using Agent-Based Simulations as A Dialogue Tool
Shaoni Wang | Published Friday, May 09, 2025This model aims to replicate the evolution of opinions and behaviours on a communal plan over time. It also aims to foster community dialogue on simulation outcomes, promoting inclusivity and engagement. Individuals (referred to as agents), grouped based on Sinus Milieus (Groh-Samberg et al., 2023), face a binary choice: support or oppose the plan. Motivated by experiential, social, and value needs (Antosz et al., 2019), their decision is influenced by how well the plan aligns with these fundamental needs.
Agent-Based Model for Multiple Team Membership (ABMMTM)
Andrew Collins | Published Thursday, April 03, 2025The Agent-Based Model for Multiple Team Membership (ABMMTM) simulates design teams searching for viable design solutions, for a large design project that requires multiple design teams that are working simultaneously, under different organizational structures; specifically, the impact of multiple team membership (MTM). The key mechanism under study is how individual agent-level decision-making impacts macro-level project performance, specifically, wage cost. Each agent follows a stochastic learning approach, akin to simulated annealing or reinforcement learning, where they iteratively explore potential design solutions. The agent evaluates new solutions based on a random-walk exploration, accepting improvements while rejecting inferior designs. This iterative process simulates real-world problem-solving dynamics where designers refine solutions based on feedback.
As a proof-of-concept demonstration of assessing the macro-level effects of MTM in organizational design, we developed this agent-based simulation model which was used in a simulation experiment. The scenario is a system design project involving multiple interdependent teams of engineering designers. In this scenario, the required system design is split into three separate but interdependent systems, e.g., the design of a satellite could (trivially) be split into three components: power source, control system, and communication systems; each of three design team is in charge of a design of one of these components. A design team is responsible for ensuring its proposed component’s design meets the design requirement; they are not responsible for the design requirements of the other components. If the design of a given component does not affect the design requirements of the other components, we call this the uncoupled scenario; otherwise, it is a coupled scenario.
Human-in-the-loop Experiment of the Strategic Coalition Formation using the glove game
Andrew Collins | Published Monday, November 23, 2020 | Last modified Wednesday, June 22, 2022The purpose of the model is to collect information on human decision-making in the context of coalition formation games. The model uses a human-in-the-loop approach, and a single human is involved in each trial. All other agents are controlled by the ABMSCORE algorithm (Vernon-Bido and Collins 2020), which is an extension of the algorithm created by Collins and Frydenlund (2018). The glove game, a standard cooperative game, is used as the model scenario.
The intent of the game is to collection information on the human players behavior and how that compares to the computerized agents behavior. The final coalition structure of the game is compared to an ideal output (the core of the games).
Displaying 10 of 136 results for "Emily S Ihara" clear search