Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 157 results for "Andreas Ihrig" clear search
Cultural Spread
Salvador Pardo Gordó Salvador Pardo-Gordó | Published Thursday, April 02, 2015 | Last modified Thursday, April 23, 2020The purpose of the model is to simulate the cultural hitchhiking hypothesis to explore how neutral cultural traits linked with advantageous traits spread together over time
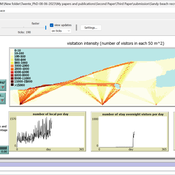
Sandy Beach Visitor Flow: An Agent-Based Model
Elham Bakhshianlamouki | Published Thursday, March 14, 2024The model is intended to simulate visitor spatial and temporal dynamics, encompassing their numbers, activities, and distribution along a coastline influenced by beach landscape design. Our primary focus is understanding how the spatial distribution of services and recreational facilities (e.g., beach width, entrance location, recreational facilities, parking availability) impacts visitation density. Our focus is not on tracking the precise visitation density but rather on estimating the areas most affected by visitor activity. This comprehension allows for assessing the diverse influences of beach layouts on spatial visitor density and, consequently, on the landscape’s biophysical characteristics (e.g., vegetation, fauna, and sediment features).
Incentives for data sharing
Flaminio Squazzoni Federico Bianchi Thomas Klebel Tony Ross-Hellauer | Published Thursday, October 02, 2025Although beneficial to scientific development, data sharing is still uncommon in many research areas. Various organisations, including funding agencies that endorse open science, aim to increase its uptake. However, estimating the large-scale implications of different policy interventions on data sharing by funding agencies, especially in the context of intense competition among academics, is difficult empirically. Here, we built an agent-based model to simulate the effect of different funding schemes (i.e., highly competitive large grants vs. distributive small grants), and varying intensity of incentives for data sharing on the uptake of data sharing by academic teams strategically adapting to the context.

Peer reviewed Ideal Free Distribution of Mobile Pastoralists in the Logone Floodplain, Cameroon
Jeff Cronley Andrew Yoak Mark Moritz Hongyang Pi Ian M Hamilton Paul Maddock | Published Thursday, June 19, 2014 | Last modified Saturday, January 06, 2018The purpose of the model is to examine whether and how mobile pastoralists are able to achieve an Ideal Free Distribution (IFD).
Parental choices, children's skills, and skill inequality: An agent-based model implemented in Python
Andrés Cardona | Published Thursday, October 30, 2014The model explores the emergence of inequality in cognitive and socio-emotional skills at the societal level within and across generations that results from differences in parental investment behavior during childhood and adolescence.

Peer reviewed An Agent-Based Model of Status Construction in Task Focused Groups
Andreas Flache Rafael Wittek André Grow | Published Sunday, May 18, 2014 | Last modified Tuesday, June 16, 2015The model simulates interactions in small, task focused groups that might lead to the emergence of status beliefs among group members.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Peer reviewed A Model of Global Diversity and Local Consensus in Status Beliefs
André Grow Andreas Flache Rafael Wittek | Published Wednesday, March 01, 2017 | Last modified Wednesday, October 25, 2017This model makes it possible to explore how network clustering and resistance to changing existing status beliefs might affect the spontaneous emergence and diffusion of such beliefs as described by status construction theory.

The PARSO_demo Model
Davide Secchi | Published Tuesday, November 05, 2019This model explores different aspects of the formation of urban neighbourhoods where residents believe in values distant from those dominant in society. Or, at least, this is what the Danish government beliefs when they discuss their politics about parallel societies. This simulation is set to understand (a) whether these alternative values areas form and what determines their formation, (b) if they are linked to low or no income residents, and (c) what happens if they disappear from the map. All these three points are part of the Danish government policy. This agent-based model is set to understand the boundaries and effects of this policy.
PSMED - Patagonia Simple Model of Ethnic Differentiation
Xavier Vilà Joan A Barceló J A Cuesta Florencia Del Castillo Ricardo Del Olmo José M Galán Laura Mameli Francisco J Miguel David Poza José I Santos | Published Tuesday, December 10, 2013Patagonia PSMED is an agent-based model designed to study a simple case of Evolution of Ethnic Differentiation. It replicates how can hunter-gatherer societies evolve and built cultural identities as a consequence of the way they interacted.
Displaying 10 of 157 results for "Andreas Ihrig" clear search