Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 561 results for "Niklas Hase" clear search
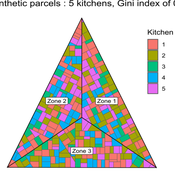
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
Asymmetric Demographic Hysteresis in a Spatial Agent-Based Urban System
Chen Shen | Published Friday, July 24, 2026This paper develops a spatial agent-based model to examine how fertility regime shifts reshape population concentration and wealth distribution in an abstract urban system. Migration decisions combine population preference, cultural homophily, expected net income, and resource endowment through a standardised softmax utility. The design is deliberately stylised: it is not calibrated to a particular country or city system, but is intended to isolate the feedbacks linking migration, fertility, urban scaling, and accumulated wealth.
The simulations reveal robust directional asymmetry. When fertility shifts from low to high, population concentration responds rapidly; when fertility shifts from high to low, concentration declines only after a detectable delay and may temporarily continue in the previous direction. Wealth adds a second layer of hysteresis: cell total-wealth concentration follows population concentration with delay, cell mean-wealth inequality and system-level wealth indicators are slower still, and phase-space trajectories form loops rather than collapsing onto a single population–wealth curve. Robustness experiments indicate that longer fertility cycles, wider mobility neighbourhoods, and smoother resource landscapes change the magnitude of delay and overshoot, but do not remove the qualitative asymmetry. The paper argues that demographic decline should be understood not as the mirror image of demographic expansion, but as a path-dependent transition mediated by fast migration-income feedbacks and slower fertility, cohort, culture, and wealth mechanisms.
RaMDry - Rangeland Model in Drylands
Pascal Fust Eva Schlecht | Published Friday, January 05, 2018 | Last modified Friday, April 01, 2022RaMDry allows to study the dynamic use of forage ressources by herbivores in semi-arid savanna with an emphasis on effects of change of climate and management. Seasonal dynamics affects the amount and the nutritional values of the available forage.
Potato late blight model
Francine Pacilly | Published Friday, April 13, 2018The purpose of the model is to simulate the spatial dynamics of potato late blight to analyse whether resistant varieties can be used effectively for sustainable disease control. The model represents an agricultural landscape with potato fields and data of a Dutch agricultural region is used as input for the model. We simulated potato production, disease spread and pathogen evolution during the growing season (April to September) for 36 years. Since late blight development and crop growth is weather dependent, measured weather data is used as model input. A susceptible and late blight resistant potato variety are distinguished. The resistant variety has a potentially lower yield but cannot get infected with the disease. However, during the growing season virulent spores can emerge as a result of mutations during spore production. This new virulent strain is able to infect the resistant fields, resulting in resistance breakdown. The model shows how disease severity, resistance durability and potato yield are affected by the fraction of fields across a landscape with a disease-resistant potato variety.

Peer reviewed Zimbabwe Agro-Pastoral Management Model (ZAPMM): Musimboti wevanhu, zvipfuo nezvirimwa
MV Eitzel Solera Kleber Tulio Neves Jon Solera Kenneth B Wilson Abraham Mawere Ndlovu Aaron C Fisher André Veski Oluwasola E Omoju Emmanuel Mhike Hove | Published Tuesday, June 19, 2018This model has been created with and for the researcher-farmers of the Muonde Trust (http://www.muonde.org/), a registered Zimbabwean non-governmental organization dedicated to fostering indigenous innovation. Model behaviors and parameters (mashandiro nemisiyano nedzimwe model) derive from a combination of literature review and the collected datasets from Muonde’s long-term (over 30 years) community-based research. The goals of this model are three-fold (muzvikamu zvitatu):
A) To represent three components of a Zimbabwean agro-pastoral system (crops, woodland grazing area, and livestock) along with their key interactions and feedbacks and some of the human management decisions that may affect these components and their interactions.
B) To assess how climate variation (implemented in several different ways) and human management may affect the sustainability of the system as measured by the continued provisioning of crops, livestock, and woodland grazing area.
C) To provide a discussion tool for the community and local leaders to explore different management strategies for the agro-pastoral system (hwaro/nzira yekudyidzana kwavanhu, zvipfuo nezvirimwa), particularly in the face of climate change.
Peer reviewed BAMERS: Macroeconomic effect of extortion
Alejandro Platas López Alejandro Guerra-Hernández | Published Monday, March 23, 2020 | Last modified Sunday, July 26, 2020Inspired by the European project called GLODERS that thoroughly analyzed the dynamics of extortive systems, Bottom-up Adaptive Macroeconomics with Extortion (BAMERS) is a model to study the effect of extortion on macroeconomic aggregates through simulation. This methodology is adequate to cope with the scarce data associated to the hidden nature of extortion, which difficults analytical approaches. As a first approximation, a generic economy with healthy macroeconomics signals is modeled and validated, i.e., moderate inflation, as well as a reasonable unemployment rate are warranteed. Such economy is used to study the effect of extortion in such signals. It is worth mentioning that, as far as is known, there is no work that analyzes the effects of extortion on macroeconomic indicators from an agent-based perspective. Our results show that there is significant effects on some macroeconomics indicators, in particular, propensity to consume has a direct linear relationship with extortion, indicating that people become poorer, which impacts both the Gini Index and inflation. The GDP shows a marked contraction with the slightest presence of extortion in the economic system.

BEGET Classic
Kristin Crouse | Published Monday, November 11, 2019 | Last modified Monday, November 25, 2019BEGET Classic includes previous versions used in the classroom and for publication. Please check out the latest version of B3GET here, which has several user-friendly features such as directly importing and exporting genotype and population files.
The classic versions of B3GET include: version one and version three were used in undergraduate labs at the University of Minnesota to demonstrate principles in primate behavioral ecology; version two first demonstrated proof of concept for creating virtual biological organisms using decision-vector algorithms; version four was presented at the 2017 annual meeting at the American Association of Physical Anthropologists; version five was presented in a 2019 publication from the Journal of Human Evolution (Crouse, Miller, and Wilson, 2019).
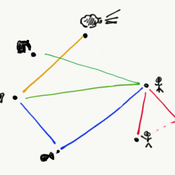
RBM - A Relation-based model - a fishery implementation
Nanda Wijermans Maja Schlüter Anja Klein Tilman Hertz | Published Monday, March 17, 2025The Relation-Based Model (RBM) purpose is to operationalise (a form of) process-relational (PR) thinking to serve as a thinking tool for process-relational thinking among social-ecological system (SES) researchers. The development of this model itself has been a ‘Proof of concept’- exercise to see whether we actually represent process-relational thinking in a methodology that is entity-based (ABM).
The target of the agent-based model is to show the emergence, change and disappearance of fishing assemblages (focusing on processes of self-organisation) in a Mexican fishery using a process-relational view. From this view, a fishery is regarded as an assemblage in which fishing can be enabled, fishing can occur, and fish can be bought/sold. These core doings - or sub-assemblages or capacities - maintain the assemblage. Each (sub)assemblage reflects different actualisations of constellations of relations and elements (buyers, fishers, fuel, permits, vessels and wind). The RBM thereby reflects an artificial fishery in which agents (elements) and their links (relations) engage in (enabling) fishing and buying/selling.

Peer reviewed MOOvPOP
Matthew Gompper Aniruddha Belsare Joshua J Millspaugh | Published Monday, April 10, 2017 | Last modified Saturday, April 19, 2025MOOvPOP is designed to simulate population dynamics (abundance, sex-age composition and distribution in the landscape) of white-tailed deer (Odocoileus virginianus) for a selected sampling region.
Displaying 10 of 561 results for "Niklas Hase" clear search