Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1212 results for "Aad Kessler" clear search

MCR Model
Davide Secchi Nuno R Barros De Oliveira | Published Friday, July 22, 2016 | Last modified Saturday, January 23, 2021The aim of the model is to define when researcher’s assumptions of dependence or independence of cases in multiple case study research affect the results — hence, the understanding of these cases.

Demand Planning Model
Iris Lorscheid Jonas Hauke Matthias Meyer | Published Wednesday, October 04, 2017Demand planning requires processing of distributed information. In this process, individuals, their properties and interactions play a crucial role. This model is a computational testbed to investigate these aspects with respect to forecast accuracy.

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.

Peer reviewed ArchMatNet: Archaeological Material Networks
Claudine Gravel-Miguel Robert Bischoff Cecilia Padilla-Iglesias | Published Monday, February 20, 2023The purpose of the model is to investigate how different factors affect the ability of researchers to reconstruct prehistoric social networks from artifact stylistic similarities, as well as the overall diversity of cultural traits observed in archaeological assemblages. Given that cultural transmission and evolution is affected by multiple interacting phenomena, our model allows to simultaneously explore six sets of factors that may condition how social networks relate to shared culture between individuals and groups:
- Factors relating to the structure of social groups
- Factors relating to the cultural traits in question
- Factors relating to individual learning strategies
- Factors relating to the environment
…
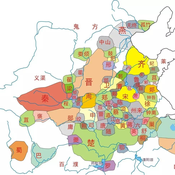
Unification-Conditions-of-Civilization-Patterns-Multi-Agent-Modeling-of-Human-History
zhuo zhang | Published Friday, May 27, 2022 | Last modified Sunday, May 29, 2022The model of Chinese and Western civilization patterns can help understand how civilizations formed, how they evolved by themselves, and the difference between the unity of China and the disunity of the Western. The previous research had examined historical phenomena about civilization patterns with subjective, static, local, and inductive methods. Therefore, we propose a general model of history dynamics for civilizations pattern, which contains both China and the West, to improve our understanding of civilization formation and the factors influencing the pattern of civilization. And at the same time, the model is used to find the boundary conditions of two different patterns.
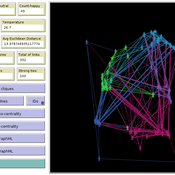
Cellular automata model of social networks
Rubens de Almeida Zimbres | Published Tuesday, August 02, 2022This project was developed during the Santa Fe course Introduction to Agent-Based Modeling 2022. The origin is a Cellular Automata (CA) model to simulate human interactions that happen in the real world, from Rubens and Oliveira (2009). These authors used a market research with real people in two different times: one at time zero and the second at time zero plus 4 months (longitudinal market research). They developed an agent-based model whose initial condition was inherited from the results of the first market research response values and evolve it to simulate human interactions with Agent-Based Modeling that led to the values of the second market research, without explicitly imposing rules. Then, compared results of the model with the second market research. The model reached 73.80% accuracy.
In the same way, this project is an Exploratory ABM project that models individuals in a closed society whose behavior depends upon the result of interaction with two neighbors within a radius of interaction, one on the relative “right” and other one on the relative “left”. According to the states (colors) of neighbors, a given cellular automata rule is applied, according to the value set in Chooser. Five states were used here and are defined as levels of quality perception, where red (states 0 and 1) means unhappy, state 3 is neutral and green (states 3 and 4) means happy.
There is also a message passing algorithm in the social network, to analyze the flow and spread of information among nodes. Both the cellular automaton and the message passing algorithms were developed using the Python extension. The model also uses extensions csv and arduino.

Peer reviewed An agent-based model for brain drain
Furkan Gürsoy Bertan Badur | Published Wednesday, March 03, 2021 | Last modified Friday, March 12, 2021An agent-based model for the emigration of highly-skilled labour.
We hypothesise that there are two main factors that impact the decision and ability to move abroad: desire to maximise individual utility and network effects. Accordingly, several factors play role in brain drain such as the overall economic and social differences between the home and host countries, people’s ability and capacity to obtain good jobs and start a life abroad, the barriers of moving abroad, and people’s social network who are already working abroad.

The uFUNK Model
Davide Secchi | Published Monday, August 31, 2020The agent-based simulation is set to work on information that is either (a) functional, (b) pseudo-functional, (c) dysfunctional, or (d) irrelevant. The idea is that a judgment on whether information falls into one of the four categories is based on the agent and its network. In other words, it is the agents who interprets a particular information as being (a), (b), (c), or (d). It is a decision based on an exchange with co-workers. This makes the judgment a socially-grounded cognitive exercise. The uFUNK 1.0.2 Model is set on an organization where agent-employee work on agent-tasks.
Fragile, Resilient, Asymmetric: An Agent-Based Stress Test of European Cooperation under Geopolitical Shocks (2024-2040)
Alessandro Brugnoletti | Published Thursday, July 16, 2026An empirically calibrated agent-based model of cooperation among 14 EU member states. Adaptive state-agents update their cooperation propensity through behavioural inertia, influence along the observed intra-EU trade network (IMF bilateral flows), and repeated-game payoff indicators built from verified Eurostat, Eurobarometer and IMF data (2021-2024). An anchored logistic mapping makes the observed configuration stationary in the absence of shocks, so outcomes read as deviations from the empirical baseline. The model stress-tests European cooperation to 2040 under five scenarios of increasing severity, from a baseline to a Taiwan Strait crisis counterfactual, with 1,000 Monte Carlo replications and a full sensitivity suite (one-factor-at-a-time, joint parameter sampling, breaking-point analysis, alternative functional form). Documented with the ODD protocol; self-testing and fully reproducible under fixed seeds.
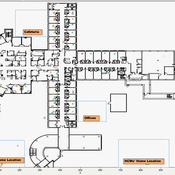
Knowledge Sharing in a Hospital
bpint Emily Molfino Joshua Goldstein Kathryn Schaefer Ziemer Mark Orr Bryan Lewis Jose Jimenez | Published Friday, January 27, 2023Organizations are complex systems comprised of many dynamic and evolving interaction patterns among individuals and groups. Understanding these interactions and how patterns, such as informal structures and knowledge sharing behavior, emerge are crucial to creating effective and efficient organizations. To explore such organizational dynamics, the agent-based model integrates a cognitive model, dynamic social networks, and a physical environment.
Displaying 10 of 1212 results for "Aad Kessler" clear search