Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 106 results learning clear search
Anxiety-to-Approach Agent-Based Model (Netlogo)
Marie Lisa Kogler | Published Tuesday, April 04, 2023An Agent-Based Model to simulate agent reactions to threatening information based on the anxiety-to-approach framework of Jonas et al. (2014).
The model showcases the framework of BIS/BAS (inhibitory and approach motivated behavior) for the case of climate information, including parameters for anxiety, environmental awareness, climate scepticism and pro-environmental behavior intention.
Agents receive external information according to threat-level and information frequency. The population dynamic is based on the learning from that information as well as social contagion mechanisms through a scale-free network topology.
The model uses Netlogo 6.2 and the network extension.
…
The S-uFUNK Model
Davide Secchi | Published Friday, March 17, 2023This version 2.1.0 of the uFunk model is about setting a business strategy (the S in the name) for an organization. A team of managers (or executives) meet and discuss various options on the strategy for the firm. There are three aspects that they have to agree on to set the strategic positioning of the organization.
The discussion is on market, stakeholders, and resources. The team (it could be a business strategy task force) considers various aspects of these three elements. The resources they use to develop the discussion can come from a traditional approach to strategy or from non-traditional means (e.g., so-called serious play, creativity and imagination techniques).
The S-uFunk 2.1.0 Model wants to understand to which extent cognitive means triggered by traditional and non-traditional resources affect the making of the strategy process.

Peer reviewed ArchMatNet: Archaeological Material Networks
Claudine Gravel-Miguel Robert Bischoff Cecilia Padilla-Iglesias | Published Monday, February 20, 2023The purpose of the model is to investigate how different factors affect the ability of researchers to reconstruct prehistoric social networks from artifact stylistic similarities, as well as the overall diversity of cultural traits observed in archaeological assemblages. Given that cultural transmission and evolution is affected by multiple interacting phenomena, our model allows to simultaneously explore six sets of factors that may condition how social networks relate to shared culture between individuals and groups:
- Factors relating to the structure of social groups
- Factors relating to the cultural traits in question
- Factors relating to individual learning strategies
- Factors relating to the environment
…
NeoCOOP: The Neolithic Cooperation Model
Brandon Gower-Winter | Published Saturday, February 11, 2023NeoCOOP is an iteration-based ABM that uses Reinforcement Learning and Artificial Evolution as adaptive-mechanisms to simulate the emergence of resource trading beliefs among Neolithic-inspired households.

Peer reviewed Reduced Mobility Transition Model (R-MoTMo)
Gesine A. Steudle Sarah Wolf Steffen Fürst | Published Tuesday, December 06, 2022The Mobility Transition Model (MoTMo) is a large scale agent-based model to simulate the private mobility demand in Germany until 2035. Here, we publish a very much reduced version of this model (R-MoTMo) which is designed to demonstrate the basic modelling ideas; the aim is by abstracting from the (empirical, technological, geographical, etc.) details to examine the feed-backs of individual decisions on the socio-technical system.
Peer reviewed Dynamic Equilibria Prediction: Experience-Weighted Attraction (EWA), Python Implementation
Vinicius Ferraz | Published Friday, December 02, 2022This project is based on a Jupyter Notebook that describes the stepwise implementation of the EWA model in bi-matrix ( 2×2 ) strategic-form games for the simulation of economic learning processes. The output is a dataset with the simulated values of Attractions, Experience, selected strategies, and payoffs gained for the desired number of rounds and periods. The notebook also includes exploratory data analysis over the simulated output based on equilibrium, strategy frequencies, and payoffs.
NK model for multilevel adaptation
Dario Blanco Fernandez | Published Wednesday, November 30, 2022Previous research on organizations often focuses on either the individual, team, or organizational level. There is a lack of multidimensional research on emergent phenomena and interactions between the mechanisms at different levels. This paper takes a multifaceted perspective on individual learning and autonomous group formation and turnover. To analyze interactions between the two levels, we introduce an agent-based model that captures an organization with a population of heterogeneous agents who learn and are limited in their rationality. To solve a task, agents form a group that can be adapted from time to time. We explore organizations that promote learning and group turnover either simultaneously or sequentially and analyze the interactions between the activities and the effects on performance. We observe underproportional interactions when tasks are interdependent and show that pushing learning and group turnover too far might backfire and decrease performance significantly.
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
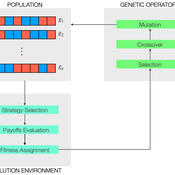
Peer reviewed Evolutionary Economic Learning Simulation: A Genetic Algorithm for Dynamic 2x2 Strategic-Form Games in Python
Vinicius Ferraz Thomas Pitz | Published Friday, April 08, 2022This project combines game theory and genetic algorithms in a simulation model for evolutionary learning and strategic behavior. It is often observed in the real world that strategic scenarios change over time, and deciding agents need to adapt to new information and environmental structures. Yet, game theory models often focus on static games, even for dynamic and temporal analyses. This simulation model introduces a heuristic procedure that enables these changes in strategic scenarios with Genetic Algorithms. Using normalized 2x2 strategic-form games as input, computational agents can interact and make decisions using three pre-defined decision rules: Nash Equilibrium, Hurwicz Rule, and Random. The games then are allowed to change over time as a function of the agent’s behavior through crossover and mutation. As a result, strategic behavior can be modeled in several simulated scenarios, and their impacts and outcomes can be analyzed, potentially transforming conflictual situations into harmony.
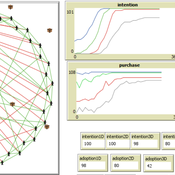
Diffusion of goods with multiple characteristics and price premiums
Pedro López Merino | Published Friday, February 18, 2022An agent-based model for the diffusion of innovations with multiple characteristics and price-premiums
Displaying 10 of 106 results learning clear search