Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 82 results for "Luis Fernando Medina" clear search
An agent-based model to study the effects of trust in coalition formation
Luis Gustavo Nardin | Published Wednesday, August 31, 2011 | Last modified Saturday, April 27, 2013This model is an agent-based simulation that consists of agents who play the spatial prisioner’s dilemma game with coalition formation. The coalition dynamics are mainly influenced by how much the agents trust their leaders. The main objective is provide a simulation model to enable the analysis of the impacts that the use of trust may cause in coalition formation.
Peer reviewed E³-MAN. An Institutionally-guided multi-agent. Model for fair and efficient negotiation.
José luis bustelo | Published Monday, September 01, 2025Negotiation plays a fundamental role in shaping human societies, underpinning conflict resolution, institutional design, and economic coordination. This article introduces E³-MAN, a novel multi-agent model for negotiation that integrates individual utility maximization with fairness and institutional legitimacy. Unlike classical approaches grounded solely in game theory, our model incorporates Bayesian opponent modeling, transfer learning from past negotiation domains, and fallback institutional rules to resolve deadlocks. Agents interact in dynamic environments characterized by strategic heterogeneity and asymmetric information, negotiating over multidimensional issues under time constraints. Through extensive simulation experiments, we compare E³-MAN against the Nash bargaining solution and equal-split baselines using key performance metrics: utilitarian efficiency, Nash social welfare, Jain fairness index, Gini coefficient, and institutional compliance. Results show that E³-MAN achieves near-optimal efficiency while significantly improving distributive equity and agreement stability. A legal application simulating multilateral labor arbitration demonstrates that institutional default rules foster more balanced outcomes and increase negotiation success rates from 58% to 98%. By combining computational intelligence with normative constraints, this work contributes to the growing field of socially aware autonomous agents. It offers a virtual laboratory for exploring how simple institutional interventions can enhance justice, cooperation, and robustness in complex socio-legal systems.
Influence with over-confident agents
Juliette Rouchier Emily Tanimura | Published Wednesday, October 21, 2015Agents can influence each other if they are close enough in knowledge. The probability to convince with good knowledge and number of agents have an impact on the dissemination of knowledge.
Dental Routine Check-Up
Peyman Shariatpanahi Afshin Jafari | Published Thursday, March 10, 2016 | Last modified Monday, April 08, 2019We develop an agent-based model for collective behavior of routine medical check-ups, and specifically dental visits, in a social network.
Opinion dynamics and collective risk perception: An ABM model of institutional and media communication about disasters - Code and Datasets
danielevilone | Published Tuesday, October 06, 2020The O.R.E. (Opinions on Risky Events) model describes how a population of interacting individuals process information about a risk of natural catastrophe. The institutional information gives the official evaluation of the risk; the agents receive this communication, process it and also speak to each other processing further the information. The description of the algorithm (as it appears also in the paper) can be found in the attached file OREmodel_description.pdf.
The code (ORE_model.c), written in C, is commented. Also the datasets (inputFACEBOOK.txt and inputEMAILs.txt) of the real networks utilized with this model are available.
For any questions/requests, please write me at daniele.vilone@gmail.com
Growing Unpopular Norms. A Network-Situated ABM of Norm Choice.
C Merdes | Published Tuesday, November 22, 2016 | Last modified Saturday, March 17, 2018The model’s purpose is to provide a potential explanation for the emergence, sustenance and decline of unpopular norms based on pluralistic ignorance on a social network.
A simple agent-based spatial model of the economy
Bernardo Alves Furtado Isaque Daniel Rocha Eberhardt | Published Thursday, March 10, 2016 | Last modified Tuesday, November 22, 2016The modeling includes citizens, bounded into families; firms and governments; all of them interacting in markets for goods, labor and real estate. The model is spatial and dynamic.

Social Innovation Model
Jiin Jung | Published Monday, April 28, 2025This research aims to uncover the micro-mechanisms that drive the macro-level relationship between cultural tolerance and innovation. We focus on the indirect influence of minorities—specifically, workers with diverse domain expertise—within collaboration networks. We propose that minority influence from individuals with different expertise can serve as a key driver of organizational innovation, particularly in dynamic market environments, and that cultural tolerance is critical for enabling such minority-induced innovation. Our model demonstrates that seemingly conflicting empirical patterns between cultural tightness/looseness and innovation can emerge from the same underlying micro-mechanisms, depending on parameter values. A systematic simulation experiment revealed an optimal cultural configuration: a medium level of tolerance (t = 0.6) combined with low consistency (κ = 0.05) produced the fastest adaptation to abrupt market changes. These findings provide evidence that indirect minority influence is a core micro-mechanism linking cultural tolerance to innovation.
PercolationPrice
Koen Frenken Luis Izquierdo Paolo Zeppini | Published Thursday, December 21, 2017 | Last modified Thursday, May 03, 2018This model simulate product diffusion on different social network structures.
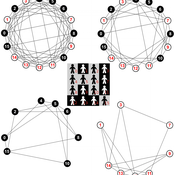
Mesoscopic Effects in an Agent-Based Bargaining Model in Regular Lattices
David Poza José Manuel Galán Ordax José Santos Adolfo López-Paredes | Published Thursday, February 02, 2017 | Last modified Wednesday, April 25, 2018We propose an agent-based model where a fixed finite population of tagged agents play iteratively the Nash demand game in a regular lattice. The model extends the bargaining model by Axtell, Epstein and Young.
Displaying 10 of 82 results for "Luis Fernando Medina" clear search