Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 364 results for "Miriam C. Kopels" clear search
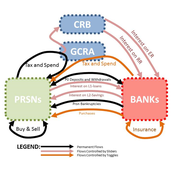
An Agent-Based Model of Insurance Customer Behaviour with Word of Mouth Network in C#
Rei England Iqbal Owadally Douglas Wright | Published Friday, March 04, 2022This is an agent-based model with two types of agents: customers and insurers. Insurers are price-takers who choose how much to spend on their service quality, and customers evaluate insurers based on premium, brand preference, and their perceived service quality. Customers are also connected in a small-world network and may share their opinions with their network.
The ABM contains two types of agents: insurers and customers. These act within the environment of a motor insurance market. At each simulation, the model undergoes the following steps:
- Network generation: At the start of the simulation, the model generates a small world network of social links between the customers, and randomly assigns each customer to an initial insurer ...
05 CmLab V1.17 – Conservation of Money Laboratory
Garvin Boyle | Published Saturday, April 15, 2017In CmLab we explore the implications of the phenomenon of Conservation of Money in a modern economy. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
Human Resource Management Parameter Experimentation Tool
Carmen Iasiello | Published Thursday, May 07, 2020 | Last modified Thursday, February 25, 2021The agent based model presented here is an explicit instantiation of the Two-Factor Theory (Herzberg et al., 1959) of worker satisfaction and dissatisfaction. By utilizing agent-based modeling, it allows users to test the empirically found variations on the Two-Factor Theory to test its application to specific industries or organizations.
Iasiello, C., Crooks, A.T. and Wittman, S. (2020), The Human Resource Management Parameter Experimentation Tool, 2020 International Conference on Social Computing, Behavioral-Cultural Modeling & Prediction and Behavior Representation in Modeling and Simulation, Washington DC.
Tutorial Models for ABM in Repast
Dave Murray-Rust | Published Monday, July 20, 2009 | Last modified Saturday, April 27, 2013First Version
Opinion dynamics and collective risk perception: An ABM model of institutional and media communication about disasters - Code and Datasets
danielevilone | Published Tuesday, October 06, 2020The O.R.E. (Opinions on Risky Events) model describes how a population of interacting individuals process information about a risk of natural catastrophe. The institutional information gives the official evaluation of the risk; the agents receive this communication, process it and also speak to each other processing further the information. The description of the algorithm (as it appears also in the paper) can be found in the attached file OREmodel_description.pdf.
The code (ORE_model.c), written in C, is commented. Also the datasets (inputFACEBOOK.txt and inputEMAILs.txt) of the real networks utilized with this model are available.
For any questions/requests, please write me at daniele.vilone@gmail.com
01b ModEco NLG V1.39 – Model Economies – The PMM
Garvin Boyle | Published Friday, April 14, 2017It is very difficult to model a sustainable intergenerational biophysical/financial economy. ModEco NLG is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.

The PARSO_demo Model
Davide Secchi | Published Tuesday, November 05, 2019This model explores different aspects of the formation of urban neighbourhoods where residents believe in values distant from those dominant in society. Or, at least, this is what the Danish government beliefs when they discuss their politics about parallel societies. This simulation is set to understand (a) whether these alternative values areas form and what determines their formation, (b) if they are linked to low or no income residents, and (c) what happens if they disappear from the map. All these three points are part of the Danish government policy. This agent-based model is set to understand the boundaries and effects of this policy.
Eliminating hepatitis C virus as a public health threat among HIV-positive men who have sex with men
Nick Scott Mark Stoove David P Wilson Olivia Keiser Carol El-Hayek Joseph Doyle Margaret Hellard | Published Wednesday, October 12, 2016 | Last modified Sunday, December 16, 2018We compare three model estimates for the time and treatment requirements to eliminate HCV among HIV-positive MSM in Victoria, Australia: a compartmental model; an ABM parametrized by surveillance data; and an ABM with a more heterogeneous population.
Threshold Public Goods Game Models with Punishment
Martin Zoričak Vladimir Gazda Gabriela Koľveková Manuela Raisová | Published Saturday, June 06, 2020This is a set of threshold public goods games models. Set consists of baseline model, endogenous shared punishment model, endogenous shared punishment model with activists and cooperation model. In each round, all agents are granted a budget of size set in GUI. Then they decide on how much they contribute to public goods and how much they keep. Public goods are provided only if the sum of contributions meets or exceeds the threshold defined in the GUI. After each round agents evaluate their strategy and payoff from this strategy.
Simple models with different types of complexity
Michael Roos | Published Tuesday, September 17, 2024 | Last modified Saturday, March 01, 2025Hierarchical problem-solving model
The model simulates a hierarchical problem-solving process in which a manager delegates parts of a problem to specialists, who attempt to solve specific aspects based on their unique skills. The goal is to examine how effectively the hierarchical structure works in solving the problem, the total cost of the process, and the resulting solution quality.
Problem-solving random network model
The model simulates a network of agents (generalists) who collaboratively solve a fixed problem by iterating over it and using their individual skills to reduce the problem’s complexity. The goal is to study the dynamics of the problem-solving process, including agent interactions, work cycles, total cost, and solution quality.
Displaying 10 of 364 results for "Miriam C. Kopels" clear search