Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 368 results for "Emmanuel Mhike Hove" clear search
ABM Simulation of Transition from Late Longshan Cultures to Early Erlitou Culture
Carmen Iasiello | Published Sunday, November 26, 2023Within the archeological record for Bronze Age Chinese culture, there continues to be a gap in our understanding of the sudden rise of the Erlitou State from the previous late Longshan chiefdoms. In order to examine this period, I developed and used an agent-based model (ABM) to explore possible socio-politically relevant hypotheses for the gap between the demise of the late Longshan cultures and rise of the first state level society in East Asia. I tested land use strategy making and collective action in response to drought and flooding scenarios, the two plausible environmental hazards at that time. The model results show cases of emergent behavior where an increase in social complexity could have been experienced if a catastrophic event occurred while the population was sufficiently prepared for a different catastrophe, suggesting a plausible lead for future research into determining the life of the time period.
The ABM published here was originally developed in 2016 and its results published in the Proceedings of the 2017 Winter Simulation Conference.
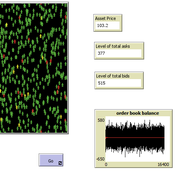
Peer reviewed A financial market with zero intelligence agents
edgarkp | Published Wednesday, March 27, 2024The model’s aim is to represent the price dynamics under very simple market conditions, given the values adopted by the user for the model parameters. We suppose the market of a financial asset contains agents on the hypothesis they have zero-intelligence. In each period, a certain amount of agents are randomly selected to participate to the market. Each of these agents decides, in a equiprobable way, between proposing to make a transaction (talk = 1) or not (talk = 0). Again in an equiprobable way, each participating agent decides to speak on the supply (ask) or the demand side (bid) of the market, and proposes a volume of assets, where this number is drawn randomly from a uniform distribution. The granularity depends on various factors, including market conventions, the type of assets or goods being traded, and regulatory requirements. In some markets, high granularity is essential to capture small price movements accurately, while in others, coarser granularity is sufficient due to the nature of the assets or goods being traded

Digital Mobility Model (DMM)
Na (Richard) Jiang Fiammetta Brandajs | Published Thursday, February 01, 2024 | Last modified Friday, February 02, 2024The purpose of the Digital Mobility Model (DMM) is to explore how a society’s adoption of digital technologies can impact people’s mobilities and immobilities within an urban environment. Thus, the model contains dynamic agents with different levels of digital technology skills, which can affect their ability to access urban services using digital systems (e.g., healthcare or municipal public administration with online appointment systems). In addition, the dynamic agents move within the model and interact with static agents (i.e., places) that represent locations with different levels of digitalization, such as restaurants with online reservation systems that can be considered as a place with a high level of digitalization. This indicates that places with a higher level of digitalization are more digitally accessible and easier to reach by individuals with higher levels of digital skills. The model simulates the interaction between dynamic agents and static agents (i.e., places), which captures how the gap between an individual’s digital skills and a place’s digitalization level can lead to the mobility or immobility of people to access different locations and services.
Peer reviewed An IBM of a fishing fleet exploiting a pelagic resource and with a fisher management system. A preliminary version.
Paul Hart | Published Tuesday, March 19, 2024A fisher directed management system was describeded by Hart (2021). It was proposed that fishers should only be allowed to exploit a resource if they collaborated in a resource management system for which they would own and be collectively responsible for. As part of the system fishers would need to follow the rules of exploitation set by the group and provide a central unit with data with which to monitor the fishery. Any fisher not following the rules would at first be fined but eventually expelled from the fishery if he/she continued to act selfishly. This version of the model establishes the dynamics of a fleet of vessels and controls overfishing by imposing fines on fishers whose income is low and who are tempted to keep fishing beyond the set quota which is established each year depending on the abundance of the fish stock. This version will later be elaborated to have interactions between the fishers including pressure to comply with the norms set by the group and which could lead to a stable management system.
Using Agent-Based Modelling and Reinforcement Learning to Study Hybrid Threats
kpadur | Published Friday, September 20, 2024Hybrid attacks coordinate the exploitation of vulnerabilities across domains to undermine trust in authorities and cause social unrest. Whilst such attacks have primarily been seen in active conflict zones, there is growing concern about the potential harm that can be caused by hybrid attacks more generally and a desire to discover how better to identify and react to them. In addressing such threats, it is important to be able to identify and understand an adversary’s behaviour. Game theory is the approach predominantly used in security and defence literature for this purpose. However, the underlying rationality assumption, the equilibrium concept of game theory, as well as the need to make simplifying assumptions can limit its use in the study of emerging threats. To study hybrid threats, we present a novel agent-based model in which, for the first time, agents use reinforcement learning to inform their decisions. This model allows us to investigate the behavioural strategies of threat agents with hybrid attack capabilities as well as their broader impact on the behaviours and opinions of other agents.
Replica of Turchin's (2003) Metaethnic Frontier model
Paul Smaldino | Published Sunday, February 15, 2026In his 2003 book, Historical Dynamics (ch. 4), Turchin describes and briefly analyzes a spatial ABM of his metaethnic frontier theory, which is essentially a formalization of a theory by Ibn Khaldun in the 14th century. In the model, polities compete with neighboring polities and can absorb them into an empire. Groups possess “asabiya”, a measure of social solidarity and a sense of shared purpose. Regions that share borders with other groups will have increased asabiya do to salient us vs. them competition. High asabiya enhances the ability to grow, work together, and hence wage war on neighboring groups and assimilate them into an empire. The larger the frontier, the higher the empire’s asabiya.
As an empire expands, (1) increased access to resources drives further growth; (2) internal conflict decreases asabiya among those who live far from the frontier; and (3) expanded size of the frontier decreases ability to wage war along all frontiers. When an empire’s asabiya decreases too much, it collapses. Another group with more compelling asabiya eventually helps establish a new empire.
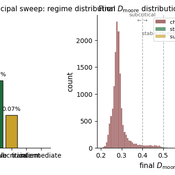
The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting
Eric Gladstone | Published Wednesday, May 13, 2026This computational model accompanies the article “The Informational Assumptions of Schelling Segregation: An Agent-Based Decomposition of Cue Inference, Cultural Schemas, and Residential Sorting.” It implements an agent-based model in which agents infer latent neighborhood-type classes from noisy non-demographic cues through schema-specific diagnostic mappings, update beliefs, and relocate when satisfaction on a preferred latent class falls below a threshold.
The model serves as a mechanism-isolation device for studying the informational architecture underlying Schelling-style residential sorting. It includes the principal sweep configuration (14,400 runs across a seven-parameter grid), a disagreement-metric sub-sweep with permutation-minimized Jensen-Shannon divergence recorded natively, controls (positive, negative, and frozen-belief), a paired-seed cue-channel perturbation experiment, and selected-cell sensitivity sweeps for cue persistence and home-biased mobility.
The full ODD protocol, parameter manifests, deterministic seed schedules, processed outputs, regenerable figure scripts, the verification test suite, and the satisfaction-mapping audit document are included. Every reported run is deterministic given a (config, seed) pair, and an included audit script verifies bit-for-bit replay on sampled runs.
An agent-based model for assessing strategies of adaptation to climate and tourism demand changes in an alpine destination
Stefano Balbi Marco Alberti | Published Monday, February 14, 2011 | Last modified Saturday, April 27, 2013The model is then used for assessing three hypothetical and contrasted infrastructure-oriented adaptation strategies for the winter tourism industry, that have been previously discussed with local stakeholders, as possible alternatives to the “business-as-usual” situation.

Exploring Creativity and Urban Development with Agent-Based Modeling
Ammar Malik Andrew Crooks Hilton Root Melanie Swartz | Published Thursday, October 30, 2014An agent-based model which explores Creativity and Urban Development
Exploring homeowners' insulation activity
Georg Holtz Emile Chappin Jonas Friege | Published Monday, June 01, 2015 | Last modified Monday, April 08, 2019We built an agent-based model to foster the understanding of homeowners’ insulation activity.
Displaying 10 of 368 results for "Emmanuel Mhike Hove" clear search