Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1146 results for "Joan A Barceló" clear search
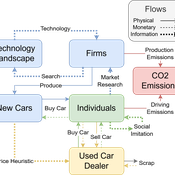
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
Model of the social game associated to the production of potato seeds in a Venezuelan region
Christhophe Sibertin-Blanc Ravi Rojas Oswaldo Terán Lisbeth Alarcón Liccia Romero | Published Monday, April 27, 2015 | Last modified Sunday, November 22, 2015This work aims at describing and simulating the (social) game around the production of potato seeds in Venezuela. It shows the effect of the identification of some actors with the production of native potato seeds (e.g., Venezuelan State´s low ident)
External shocks, agent interactions, and endogenous feedbacks--investigating system resilience with a stylized land use model
Yang Chen | Published Tuesday, March 06, 2018The purpose of the presented ABM is to explore how system resilience is affected by external disturbances and internal dynamics by using the stylized model of an agricultural land use system.
We explore land system resilience with a stylized land use model in which agents’ land use activities are affected by external shocks, agent interactions, and endogenous feedbacks. External shocks are designed as yield loss in crops, which is ubiquitous in almost every land use system where perturbations can occur due to e.g. extreme weather conditions or diseases. Agent interactions are designed as the transfer of buffer capacity from farmers who can and are willing to provide help to other farmers within their social network. For endogenous feedbacks, we consider land use as an economic activity which is regulated by markets — an increase in crop production results in lower price (a negative feedback) and an agglomeration of a land use results in lower production costs for the land use type (a positive feedback).
The Evolution of Tribalism: A Social-Ecological Model of Cooperation and Inter-group Conflict Under Pastoralism
Nicholas Seltzer | Published Monday, January 21, 2019This study investigates a possible nexus between inter-group competition and intra-group cooperation, which may be called “tribalism.” Building upon previous studies demonstrating a relationship between the environment and social relations, the present research incorporates a social-ecological model as a mediating factor connecting both individuals and communities to the environment. Cyclical and non-cyclical fluctuation in a simple, two-resource ecology drive agents to adopt either “go-it-alone” or group-based survival strategies via evolutionary selection. Novelly, this simulation employs a multilevel selection model allowing group-level dynamics to exert downward selective pressures on individuals’ propensity to cooperate within groups. Results suggest that cooperation and inter-group conflict are co-evolved in a triadic relationship with the environment. Resource scarcity increases inter-group competition, especially when resources are clustered as opposed to widely distributed. Moreover, the tactical advantage of cooperation in the securing of clustered resources enhanced selective pressure on cooperation, even if that implies increased individual mortality for the most altruistic warriors. Troubling, these results suggest that extreme weather, possibly as a result of climate change, could exacerbate conflict in sensitive, weather-dependent social-ecologies—especially places like the Horn of Africa where ecologically sensitive economic modalities overlap with high-levels of diversity and the wide-availability of small arms. As well, global development and foreign aid strategists should consider how plans may increase the value of particular locations where community resources are built or aid is distributed, potentially instigating tribal conflict. In sum, these factors, interacting with pre-existing social dynamics dynamics, may heighten inter-ethnic or tribal conflict in pluralistic but otherwise peaceful communities.
For special issue submission in JASSS.
Sensitivity of a population submitted to floods to unknown upcoming floods and parameters of the dynamics
Sylvie Huet | Published Wednesday, September 22, 2021This work is a java implementation of a study of the viability of a population submitted to floods. The population derives some benefit from living in a certain environment. However, in this environment, floods can occur and cause damage. An individual protection measure can be adopted by those who wish and have the means to do so. The protection measure reduces the damage in case of a flood. However, the effectiveness of this measure deteriorates over time. Individual motivation to adopt this measure is boosted by the occurrence of a flood. Moreover, the public authorities can encourage the population to adopt this measure by carrying out information campaigns, but this comes at a cost. People’s decisions are modelled based on the Protection Motivation Theory (Rogers1975, Rogers 1997, Maddux1983) arguing that the motivation to protect themselves depends on their perception of risk, their capacity to cope with risk and their socio-demographic characteristics.
While the control designing proper informations campaigns to remain viable every time is computed in the work presented in https://www.comses.net/codebases/e5c17b1f-0121-4461-9ae2-919b6fe27cc4/releases/1.0.0/, the aim of the present work is to produce maps of probable viability in case the serie of upcoming floods is unknown as well as much of the parameters for the population dynamics. These maps are bi-dimensional, based on the value of known parameters: the current average wealth of the population and their actual or possible future annual revenues.
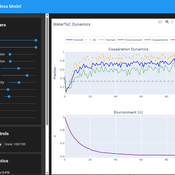
Tragedy of the Commons with Environmental Feedback: A Model of Human-AI Socio-Environmental Water Dilemma
Ivana Malcic Luka Waronig Andrew Crossley | Published Saturday, July 05, 2025 | Last modified Sunday, July 06, 2025This project is an interactive agent-based model simulating consumption of a shared, renewable resource using a game-theoretic framework with environmental feedback. The primary function of this model was to test how resource-use among AI and human agents degrades the environment, and to explore the socio-environmental feedback loops that lead to complex emergent system dynamics. We implemented a classic game theoretic matrix which decides agents´ strategies, and added a feedback loop which switches between strategies in pristine vs degraded environments. This leads to cooperation in bad environments, and defection in good ones.
Despite this use, it can be applicable for a variety of other scenarios including simulating climate disasters, environmental sensitivity to resource consumption, or influence of environmental degradation to agent behaviour.
The ABM was inspired by the Weitz et. al. (2016, https://pubmed.ncbi.nlm.nih.gov/27830651/) use of environmental feedback in their paper, as well as the Demographic Prisoner’s Dilemma on a Grid model (https://mesa.readthedocs.io/stable/examples/advanced/pd_grid.html#demographic-prisoner-s-dilemma-on-a-grid). The main innovation is the added environmental feedback with local resource replenishment.
Beyond its theoretical insights into coevolutionary dynamics, it serves as a versatile tool with several practical applications. For urban planners and policymakers, the model can function as a ”digital sandbox” for testing the impacts of locating high-consumption industrial agents, such as data centers, in proximity to residential communities. It allows for the exploration of different urban densities, and the evaluation of policy interventions—such as taxes on defection or subsidies for cooperation—by directly modifying the agents’ resource consumptions to observe effects on resource health. Furthermore, the model provides a framework for assessing the resilience of such socio-environmental systems to external shocks.
…

STiMUS-HAI: A Stigmergic–Mutualistic Agent-Based Model of Human-AI Collaboration on Shared Digital Artefacts
Yevgeny Patarakin | Published Monday, July 13, 2026STiMUS-HAI (Stigmergic–Mutualistic IMOI Model, Human-AI extension) is an agent-based model of teamwork in socio-technical systems where human and AI contributors collaborate through shared digital artefacts — wiki pages, code files, issue tickets, project cards, Scratch projects — represented as patches in a NetLogo world. It extends the human-only base model STiMUS v2.2, which established that two coordination mechanisms — stigmergy (indirect coordination through traces left in the environment) and mutualism (mutual benefit between contributors and the artefacts they tend) — can be decoupled: stigmergy decides where a contributor works, mutualism decides with what effort. STiMUS-HAI preserves this decoupling unchanged and adds two further theoretical questions: whether mixing AI agents into a human team distorts human coordination in ways that aggregate indicators hide, and whether AI’s cost to team outcomes depends on the type of work AI performs, not only on how much of it is present.
Two breeds of turtle — humans and ai-agents — follow identical target-selection, pheromone, and mutualism rules, so that any behavioural difference is attributable to team composition rather than a built-in advantage. The one designed asymmetry: AI agents never accumulate shared-mental-model and their motivation is fixed rather than adaptive. On top of this v3.0 baseline, v3.1 adds a task-type dimension to artefacts (“prediction” versus “judgment”, set via a judgment-share slider) that scales down AI edit-power specifically on judgment-requiring artefacts, and an ai-trust mechanic: humans build or lose trust in AI contributions based on the population-relative percentile rank of observed AI work quality (bottom-quartile work counts as an observed “error”), and that trust gates how much mutualistic benefit a human derives from continuing an AI’s work. Trust erodes quickly on a single error and recovers only after a streak of confirmed successes — an intentional asymmetry.

REHAB: A Role Playing Game to Explore the Influence of Knowledge and Communication on Natural Resources Management
Christophe Le Page Anne Dray Pascal Perez Claude Garcia | Published Monday, July 13, 2015 | Last modified Monday, July 13, 2015REHAB has been designed as an ice-breaker in courses dealing with ecosystem management and participatory modelling. It helps introducing the two main tools used by the Companion Modelling approach, namely role-playing games and agent-based models.
A model of opinion dynamics based on formal argumentation: application to the diffusion of the vegetarian diet
Patrick Taillandier Nicolas Salliou Rallou Thomopoulos | Published Monday, March 15, 2021 | Last modified Wednesday, January 07, 2026This generic agent-based model simulates the evolution of agent’s opinions through their exchange of arguments.
The idea behind this model is to explicitly represent the process of mental deliberation of agents from arguments to an opinion, through the use of Dung’s argumentation framework complemented by a structured description of arguments. An application of the model on the diffusion of vegetarian diets is proposed.
Simulation model replicating the five different games that were run during a workshop of the TISSS Lab
tissslab | Published Friday, April 30, 2021The three-day participatory workshop organized by the TISSS Lab had 20 participants who were academics in different career stages ranging from university student to professor. For each of the five games, the participants had to move between tables according to some pre-specified rules. After the workshop both the participant’s perception of the games’ complexities and the participants’ satisfaction with the games were recorded.
In order to obtain additional objective measures for the games’ complexities, these games were also simulated using this simulation model here. Therefore, the simulation model is an as-accurate-as-possible reproduction of the workshop games: it has 20 participants moving between 5 different tables. The rules that specify who moves when vary from game to game. Just to get an idea, Game 3 has the rule: “move if you’re sitting next to someone who is waring white or no socks”.
An exact description of the workshop games and the associated simulation models can be found in the paper “The relation between perceived complexity and happiness with decision situations: searching for objective measures in social simulation games”.
Displaying 10 of 1146 results for "Joan A Barceló" clear search