Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 244 results for "Paulien Herder" clear search
Peer reviewed A Simple Agent-Based Spatial Model of the Economy: Tools for Policy
Bernardo Furtado Isaque Daniel Rocha Eberhardt | Published Tuesday, July 05, 2022This study simulates the evolution of artificial economies in order to understand the tax relevance of administrative boundaries in the quality of life of its citizens. The modeling involves the construction of a computational algorithm, which includes citizens, bounded into families; firms and governments; all of them interacting in markets for goods, labor and real estate. The real estate market allows families to move to dwellings with higher quality or lower price when the families capitalize property values. The goods market allows consumers to search on a flexible number of firms choosing by price and proximity. The labor market entails a matching process between firms (given its location) and candidates, according to their qualification. The government may be configured into one, four or seven distinct sub-national governments, which are all economically conurbated. The role of government is to collect taxes on the value added of firms in its territory and invest the taxes into higher levels of quality of life for residents. The results suggest that the configuration of administrative boundaries is relevant to the levels of quality of life arising from the reversal of taxes. The model with seven regions is more dynamic, but more unequal and heterogeneous across regions. The simulation with only one region is more homogeneously poor. The study seeks to contribute to a theoretical and methodological framework as well as to describe, operationalize and test computer models of public finance analysis, with explicitly spatial and dynamic emphasis. Several alternatives of expansion of the model for future research are described. Moreover, this study adds to the existing literature in the realm of simple microeconomic computational models, specifying structural relationships between local governments and firms, consumers and dwellings mediated by distance.

WEEM (Woodlot Establishment and Expansion Model)
Jürgen Groeneveld Vianny Ahimbisibwe Uta Berger Melvin Lippe Susan Balaba Tumwebaze Eckhard Auch | Published Monday, September 27, 2021The agent-based model WEEM (Woodlot Establishment and Expansion Model) as described in the journal article, has been designed to make use of household socio-demographics (household status, birth, and death events of households), to better understand the temporal dynamics of woodlot in the buffer zones of Budongo protected forest reserve, Masindi district, Uganda. The results contribute to a mechanistic understanding of what determines the current gap between intention and actual behavior in forest land restoration at farm level.
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Coastal Coupled Housing and Land Markets (C-CHALMS)
Nicholas Magliocca | Published Thursday, May 18, 2017Next generation of the CHALMS model applied to a coastal setting to investigate the effects of subjective risk perception and salience decision-making on adaptive behavior by residents.
Hyperconnectivity, and Fact-Checking- Modeling Witnessing as a Traditional Coast Salish Mechanism
Adam Rorabaugh | Published Thursday, May 01, 2025An unintended consequence of low cost maritime travel may be hyperconnectedness, creating social situations where information can be readily passed before it is verified- an issue not limited to modern digitally connected societies. In traditional Coast Salish societies, the peoples of what is now Western Washington and Southwestern British Columbia, oral traditions were vertified through a process called witnessing. Witnesses would be trained to recount and verify oral history and traditional teachings at high fidelity. Here, a simple model based on dual inheritance approaches to genes and culture, is used to compare this specific form of verifying socially important information compared to modern mass communication. The model suggests that witnessing is a high fidelity form of transmitting knowledge with a low error rate, more in line with modern apprenticeships than mass communication. Social mechanisms such as witnessing provide solutions to issues faced in contemporary discourse where the validity of information and even fact checking mechanisms may be biased or counterfactual. This effort also demonstrates the utillity of using modeling approaches to highlight how specific, historically contingent institutions such as witnesses can be drawn upon to model potential solutions to contemporary issues solved in the past in traditional Coast Salish practice.
Adoption as a social marker
Paul Smaldino | Published Monday, October 17, 2016A model of innovation diffusion in a structured population with two groups who are averse to adopting a produce popular with the outgroup.
Peer reviewed Simulating the Economic Impact of Boko Haram on a Cameroonian Floodplain
Mark Moritz Nathaniel Henry Sarah Laborde | Published Saturday, October 22, 2016 | Last modified Wednesday, June 07, 2017This model examines the potential impact of market collapse on the economy and demography of fishing households in the Logone Floodplain, Cameroon.
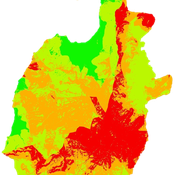
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Gert Jan Hofstede Mark R Kramer Sebastian Fajardo Andrés Bernal Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025 | Last modified Tuesday, March 24, 2026The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
Formal Organization Hierarchy and Informal Networks - "The Company Behind the Org Chart"
Tom Briggs | Published Sunday, April 18, 2021A generalized organizational agent- based model (ABM) containing both formal organizational hierarchy and informal social networks simulates organizational processes that occur over both formal network ties and informal networks.
Displaying 10 of 244 results for "Paulien Herder" clear search