Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 233 results for "G M Leighton" clear search

Kulayinjana
Christophe Le Page Arthur Perrotton Michel De Garine-Wichatitsky Barry Bitu Killion Koyisi Ferdinand Mwamba Cephus Ncube Victor Ncube Siphusisiwe Ndlovu Raphael Ngwenya Ambu Nyathi Fumbane Nyathi Patrick Sibanda Zenzo Sibanda | Published Monday, October 03, 2016a computer-based role-playing game simulating the interactions between farming activities, livestock herding and wildlife in a virtual landscape reproducing local socioecological dynamics at the periphery of Hwange National Park (Zimbabwe).
Success bias imitation increases the probability of effectively dealing with ecological disturbances
Jacopo A. Baggio Vicken Hillis | Published Thursday, April 13, 2017 | Last modified Thursday, August 02, 2018This model aims to investigate how different type of learning (social system) and disturbance specific attributes (ecological system) influence adoption of treatment strategies to treat the effects of ecological disturbances.

Animal territory formation (Reusable Building Block RBB)
Volker Grimm Stephanie Kramer-Schadt Robert Zakrzewski | Published Sunday, November 12, 2023This is a generic sub-model of animal territory formation. It is meant to be a reusable building block, but not in the plug-and-play sense, as amendments are likely to be needed depending on the species and region. The sub-model comprises a grid of cells, reprenting the landscape. Each cell has a “quality” value, which quantifies the amount of resources provided for a territory owner, for example a tiger. “Quality” could be prey density, shelter, or just space. Animals are located randomly in the landscape and add grid cells to their intial cell until the sum of the quality of all their cells meets their needs. If a potential new cell to be added is owned by another animal, competition takes place. The quality values are static, and the model does not include demography, i.e. mortality, mating, reproduction. Also, movement within a territory is not represented.
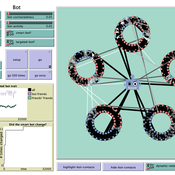
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.

Peer reviewed HUMLAND FIRE-IN-THE-HOLE agent-based model
Fulco Scherjon Anastasia Nikulina | Published Monday, October 20, 2025HUMLAND Fire-in-the-Hole is a conceptual agent-based model (ABM) designed to explore the ecological and behavioral consequences of fire-driven hunting strategies employed by hunter-gatherers, specifically Neanderthals, during the Last Interglacial period around the Neumark-Nord (Germany) archaeological site.
This model builds on and specializes the HUMLAND 1.0.0 model (Nikulina et al. 2024), integrating anthropogenic fires, elephant group behavior, and landscape response to simulate interactions between humans, megafauna, and vegetation over time.
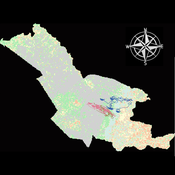
Agent modeling (ABM) as a tool to improve the mobility of “avoidant” birds in an ecological corridor in the localities of Chapinero, Teusaquillo, Barrios Unidos and Engativá of Bogotá city [Scenario 2]
Paula Alejandra Meza | Published Thursday, June 25, 2026Considering that two of the three avoider species could not reach the target area in the inittial scenario, five alternative corridor scenarios were created. In all cases, we generated a greater amount of cover area under ‘Urban forest’, including elements such as scattered trees, woody plants, wooded areas, and rows of trees. This covered type was selected since all three species use it as a regular habitat. That is the second sceneario where those ecological parks and other areas inside the capital city were boostered into “urban forest patches” or buffer points, with the idea of improving the survive of the three bird species and their movement. However one of the most restrictive specie was still having movement and survival issues.
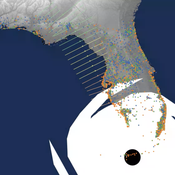
Peer reviewed CHIME ABM of Hurricane Evacuation
C Michael Barton Sean Bergin Joshua Watts Joshua Alland Rebecca Morss | Published Monday, October 18, 2021 | Last modified Tuesday, January 04, 2022The Communicating Hazard Information in the Modern Environment (CHIME) agent-based model (ABM) is a Netlogo program that facilitates the analysis of information flow and protective decisions across space and time during hazardous weather events. CHIME ABM provides a platform for testing hypotheses about collective human responses to weather forecasts and information flow, using empirical data from historical hurricanes. The model uses real world geographical and hurricane data to set the boundaries of the simulation, and it uses historical hurricane forecast information from the National Hurricane Center to initiate forecast information flow to citizen agents in the model.
Urban Teacher Lifecycle and Mobility
Yevgeny Patarakin | Published Wednesday, July 23, 2025This agent-based model simulates the lifecycle, movement, and satisfaction of teachers within an urban educational system composed of multiple universities and schools. Each teacher agent transitions through several possible roles: newcomer, university student, unemployed graduate, and employed teacher. Teachers’ pathways are shaped by spatial configuration, institutional capacities, individual characteristics, and dynamic interactions with schools and universities. Universities are assigned spatial locations with a controllable level of centralization and are characterized by academic ratings, capacity, and alumni records. Schools are distributed throughout the city, each with a limited number of vacancies, hiring requirements, and offered salaries. Teachers apply to universities based on the alignment of their personal academic profiles with institutional ratings, pursue studies, and upon graduation become candidates for employment at schools.
The employment process is driven by a decentralized matching of teacher expectations and school offers, taking into account factors such as salary, proximity, and peer similarity. Teachers’ satisfaction evolves over time, reflecting both institutional characteristics and the composition of their colleagues; low satisfaction may prompt teachers to transfer between schools within their mobility radius. Mortality and teacher attrition further shape workforce dynamics, leading to continuous recruitment of newcomers to maintain a stable population. The model tracks university reputation through the academic performance and number of alumni, and visualizes key metrics including teacher status distribution, school staffing, university alumni counts, and overall satisfaction. This structure enables the exploration of policy interventions, hiring and training strategies, and the impact of spatial and institutional design on the allocation, retention, and happiness of urban educational staff.
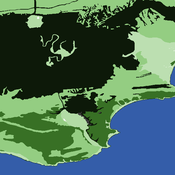
An agent-based approach to weighted decision making in the spatially and temporally variable South African Paleoscape
Colin Wren | Published Thursday, December 29, 2016This model simulates a foraging system based on Middle Stone Age plant and shellfish foraging in South Africa.
Soy2Grow-ABM-V1
Siavash Farahbakhsh | Published Monday, January 20, 2025The Soy2Grow ABM aims to simulate the adoption of soybean production in Flanders, Belgium. The model primarily considers two types of agents as farmers: 1) arable and 2) dairy farmers. Each farmer, based on its type, assesses the feasibility of adopting soybean cultivation. The feasibility assessment depends on many interrelated factors, including price, production costs, yield, disease, drought (i.e., environmental stress), social pressure, group formations, learning and skills, risk-taking, subsidies, target profit margins, tolerance to bad experiences, etc. Moreover, after adopting soybean production, agents will reassess their performance. If their performance is unsatisfactory, an agent may opt out of soy production. Therefore, one of the main outcomes to look for in the model is the number of adopters over time.
The main agents are farmers. Generally, factors influencing farmers’ decision-making are divided into seven main areas: 1) external environmental factors, 2) cooperation and learning (with slight differences depending on whether they are arable or dairy farmers), 3) crop-specific factors, 4) economics, 5) support frameworks, 6) behavioral factors, and 7) the role of mobile toasters (applicable only to dairy farmers).
Moreover, factors not only influence decision-making but also interact with each other. Specifically, external environmental factors (i.e., stress) will result in lower yield and quality (protein content). The reducing effect, identified during participatory workshops, can reach 50 %. Skills can grow and improve yield; however, their growth has a limit and follows different learning curves depending on how individualistic a farmer is. During participatory workshops, it was identified that, contrary to cooperative farmers, individualistic farmers may learn faster and reach their limits more quickly. Furthermore, subsidies directly affect revenues and profit margins; however, their impact may disappear when they are removed. In the case of dairy farmers, mobile toasters play an important role, adding toasting and processing costs to those producing soy for their animal feed consumption.
Last but not least, behavioral factors directly influence the final adoption decision. For example, high risk-taking farmers may adopt faster, whereas more conservative farmers may wait for their neighbors to adopt first. Farmers may evaluate their success based on their own targets and may also consider other crops rather than soy.
Displaying 10 of 233 results for "G M Leighton" clear search