Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 127 results for "Annemijn Peters" clear search
Peer reviewed Charging behaviour of electric vehicle drivers
Wilfried van Sark Annemijn Peters Floor Alkemade Mart van der Kam | Published Wednesday, May 08, 2019 | Last modified Tuesday, April 14, 2020This model was developed to study the combination of electric vehicles (EVs) and intermitten renewable energy sources. The model presents an EV fleet in a fictional area, divided into a residential area, an office area and commercial area. The area has renewable energy sources: wind and PV solar panels. The agents can be encouraged to charge their electric vehicles at times of renewable energy surplus by introducing different policy interventions. Other interesting variables in the model are the installed renewable energy sources, EV fleet composition and available charging infrastructure. Where possible, use emperical data as input for our model. We expand upon previous models by incorporating environmental self-identity and range anxiety as agent variables.
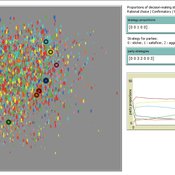
Party Competition with Opinion Dynamics
Marco Janssen | Published Sunday, June 28, 2026We combine a model of parties adjusting their position to recruit voters, and voters adjusting their opinions due to social influence and party positions.
Asymmetric two-sided matching
Naoki Shiba | Published Wednesday, January 09, 2013 | Last modified Tuesday, May 28, 2013This model is an extended version of the matching problem including the mate search problem, which is the generalization of a traditional optimization problem. The matching problem is extended to a form of asymmetric two-sided matching problem.
Imperfect knowledge and stable governance in democracies
Carlos M Fernández-Márquez Francisco Jose Vazquez Luis Fernando Medina | Published Tuesday, February 05, 2019In this paper we introduce an agent-based model of elections and government formation where voters do not have perfect knowledge about the parties’ ideological position. Although voters are boundedly rational, they are forward-looking in that they try to assess the likely impact of the different parties over the resulting government. Thus, their decision rules combine sincere and strategic voting: they form preferences about the different parties but deem some of them as inadmissible and try to block them from office. We find that the most stable and durable coalition governments emerge at intermediate levels of informational ambiguity. When voters have very poor information about the parties, their votes are scattered too widely, preventing the emergence of robust majorities. But also, voters with highly precise perceptions about the parties will cluster around tiny electoral niches with a similar aggregate effect.

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
The Effect of Individual and Collective Characteristics on Team Performance: A Model of Networked Agents Engaged in Collective Problem Solving
Amin Boroomand | Published Tuesday, March 16, 2021 | Last modified Monday, July 26, 2021This code is for an agent-based model of collective problem solving in which agents with different behavior strategies, explore the NK landscape while they communicate with their peers agents. This model is based on the famous work of Lazer, D., & Friedman, A. (2007), The network structure of exploration and exploitation.
Peer Review Model
Flaminio Squazzoni Claudio Gandelli | Published Wednesday, September 05, 2012 | Last modified Saturday, April 27, 2013This model looks at implications of author/referee interaction for quality and efficiency of peer review. It allows to investigate the importance of various reciprocity motives to ensure cooperation. Peer review is modelled as a process based on knowledge asymmetries and subject to evaluation bias. The model includes various simulation scenarios to test different interaction conditions and author and referee behaviour and various indexes that measure quality and efficiency of evaluation […]
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.
Political Competition
Marco Janssen | Published Sunday, June 28, 2026Political parties compete for voters by (re-) positioning themselves within the opinion space.
PaCE Austria Pilot Model
Ruth Meyer | Published Tuesday, June 30, 2020The objective of building a social simulation in the Populism and Civic Engagement (PaCE) project is to study the phenomenon of populism by mapping individual level political behaviour and explain the influence of agents on, and their interdependence with the respective political parties. Voters, political parties and – to some extent – the media can be viewed as forming a complex adaptive system, in which parties compete for citizens’ votes, voters decide on which party to vote for based on their respective positions with regard to particular issues, and the media may influence the salience of issues in the public debate.
This is the first version of a model exploring voting behaviour in Austria. It focusses on modelling the interaction of voters and parties in a political landscape; the effects of the media are not yet represented. Austria was chosen as a case study because it has an established populist party (the “Freedom Party” FPO), which has even been part of the government over the years.
Displaying 10 of 127 results for "Annemijn Peters" clear search