Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 361 results for "Daniel J Singer" clear search
Food Safety Inspection Model - Stores Signal with Errors
Sara Mcphee-Knowles | Published Wednesday, March 05, 2014 | Last modified Monday, April 08, 2019The Inspection Model represents a basic food safety system where inspectors, consumers and stores interact. The purpose of the model is to provide insight into an optimal level of inspectors in a food system by comparing three search strategies.
Food Safety Inspection Model - Stores Signal
Sara Mcphee-Knowles | Published Wednesday, March 05, 2014 | Last modified Monday, August 26, 2019The Inspection Model represents a basic food safety system where inspectors, consumers and stores interact. The purpose of the model is to provide insight into an optimal level of inspectors in a food system by comparing three search strategies.
(De-)Stabilising effect of diffusions
Julia Kasmire Bert Van Meeuwen Cornelis Eikelboom | Published Tuesday, August 11, 2015What is stable: the large but coordinated change during a diffusion or the small but constant and uncoordinated changes during a dynamic equilibrium? This agent-based model of a diffusion creates output that reveal insights for system stability.
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Gert Jan Hofstede Mark R Kramer Sebastian Fajardo Andrés Bernal Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
Exploring homeowners' insulation activity
Georg Holtz Emile Chappin Jonas Friege | Published Monday, June 01, 2015 | Last modified Monday, April 08, 2019We built an agent-based model to foster the understanding of homeowners’ insulation activity.
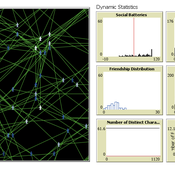
The Friendship Field
Eva Timmer Chrisja van de Kieft | Published Thursday, May 26, 2022 | Last modified Tuesday, August 30, 2022The Friendship Field model aims at modelling friendship formation based on three factors: Extraversion, Resemblance and Status, where social interaction is motivated by the Social Battery. Social Battery is one’s energy and motivation to engage in social contact. Since social contact is crucial for friendship formation, the model included Social Battery to affect social interactions. To our best knowledge, Social Battery is a yet unintroduced concept in research while it is a dynamic factor influencing the social interaction besides one’s characteristics. Extraverts’ Social Batteries charge while interacting and exhaust while being alone. Introverts’ Social Batteries charge while being alone and exhaust while interacting. The aim of the model is to illustrate the concept of Social Battery. Moreover, the Friendship Field shows patterns regarding Extraversion, Resemblance and Status including the mere-exposure effect and friendship by similarity. For the implementation of Status, Kemper’s status-power theory is used. The concept of Social Battery is also linked to Kemper’s theory on the organism as reference group. By running the model for a year (3 interactions moments per day), the friendship dynamics over time can be studied.
We presented the model at the Social Simulation Conference 2022.
A network agent-based model of ethnocentrism and intergroup cooperation
Ross Gore | Published Sunday, October 27, 2019We present a network agent-based model of ethnocentrism and intergroup cooperation in which agents from two groups (majority and minority) change their communality (feeling of group solidarity), cooperation strategy and social ties, depending on a barrier of “likeness” (affinity). Our purpose was to study the model’s capability for describing how the mechanisms of preexisting markers (or “tags”) that can work as cues for inducing in-group bias, imitation, and reaction to non-cooperating agents, lead to ethnocentrism or intergroup cooperation and influence the formation of the network of mixed ties between agents of different groups. We explored the model’s behavior via four experiments in which we studied the combined effects of “likeness,” relative size of the minority group, degree of connectivity of the social network, game difficulty (strength) and relative frequencies of strategy revision and structural adaptation. The parameters that have a stronger influence on the emerging dominant strategies and the formation of mixed ties in the social network are the group-tag barrier, the frequency with which agents react to adverse partners, and the game difficulty. The relative size of the minority group also plays a role in increasing the percentage of mixed ties in the social network. This is consistent with the intergroup ties being dependent on the “arena” of contact (with progressively stronger barriers from e.g. workmates to close relatives), and with measures that hinder intergroup contact also hindering mutual cooperation.
Peer reviewed Price Evolution with Expectations
J M Applegate Gesine Steudel Armin Haas Carlo Jaeger | Published Friday, September 10, 2021The Price Evolution with Expectations model provides the opportunity to explore the question of non-equilibrium market dynamics, and how and under which conditions an economic system converges to the classically defined economic equilibrium. To accomplish this, we bring together two points of view of the economy; the classical perspective of general equilibrium theory and an evolutionary perspective, in which the current development of the economic system determines the possibilities for further evolution.
The Price Evolution with Expectations model consists of a representative firm producing no profit but producing a single good, which we call sugar, and a representative household which provides labour to the firm and purchases sugar.The model explores the evolutionary dynamics whereby the firm does not initially know the household demand but eventually this demand and thus the correct price for sugar given the household’s optimal labour.
The model can be run in one of two ways; the first does not include money and the second uses money such that the firm and/or the household have an endowment that can be spent or saved. In either case, the household has preferences for leisure and consumption and a demand function relating sugar and price, and the firm has a production function and learns the household demand over a set number of time steps using either an endogenous or exogenous learning algorithm. The resulting equilibria, or fixed points of the system, may or may not match the classical economic equilibrium.
Peer reviewed LUCID: Land Use Competition In Drylands
Birgit Müller Gunnar Dressler Lance Robinson | Published Wednesday, April 12, 2023The Land Use Competition in Drylands (LUCID) model is a stylized agent-based model of a smallholder farming system. Its main purpose is to illustrate how competition between pastoralism and crop cultivation can affect livelihoods of households, specifically their food security. In particular, the model analyzes whether the expansion of crop cultivation may contribute to a vicious circle where an increase in cultivated area leads to higher grazing pressure on the remaining pastureland, which in turn may cause forage shortages and livestock loss for households which are then forced to further expand their cultivated area in order to increase their food security. The model does not attempt to replicate a particular case study but to generate a general understanding of mechanisms and drivers of such vicious circles and to identify possible scenarios under which such circles may be prevented.
The model is inspired by observations of the Borana land use system in Southern Ethiopia. The climatic and ecological conditions of the Borana zone favor pastoralism, and traditionally livelihoods have been based mainly on livestock keeping. Recent years, however, have seen an advancement of crop cultivation as a coping strategy, e.g., to compensate the loss of livestock, even though crop yields are low on average and successful harvests are infrequent.
In the model, it is possible to evaluate patterns of individual (single household) as well as overall (across all households) consumption and food security, depending on a range of ecological, climatic and management parameters.
Displaying 10 of 361 results for "Daniel J Singer" clear search