Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 217 results for "Andreas Flache" clear search
Peer reviewed MADTOR: Model for Assessing Drug Trafficking Organizations Resilience
Deborah Manzi | Published Friday, February 23, 2024 | Last modified Friday, February 27, 2026Criminal organizations operate in complex changing environments. Being flexible and dynamic allows criminal networks not only to exploit new illicit opportunities but also to react to law enforcement attempts at disruption, enhancing the persistence of these networks over time. Most studies investigating network disruption have examined organizational structures before and after the arrests of some actors but have disregarded groups’ adaptation strategies.
MADTOR simulates drug trafficking and dealing activities by organized criminal groups and their reactions to law enforcement attempts at disruption. The simulation relied on information retrieved from a detailed court order against a large-scale Italian drug trafficking organization (DTO) and from the literature.
The results showed that the higher the proportion of members arrested, the greater the challenges for DTOs, with higher rates of disrupted organizations and long-term consequences for surviving DTOs. Second, targeting members performing specific tasks had different impacts on DTO resilience: targeting traffickers resulted in the highest rates of DTO disruption, while targeting actors in charge of more redundant tasks (e.g., retailers) had smaller but significant impacts. Third, the model examined the resistance and resilience of DTOs adopting different strategies in the security/efficiency trade-off. Efficient DTOs were more resilient, outperforming secure DTOs in terms of reactions to a single, equal attempt at disruption. Conversely, secure DTOs were more resistant, displaying higher survival rates than efficient DTOs when considering the differentiated frequency and effectiveness of law enforcement interventions on DTOs having different focuses in the security/efficiency trade-off.
Overall, the model demonstrated that law enforcement interventions are often critical events for DTOs, with high rates of both first intention (i.e., DTOs directly disrupted by the intervention) and second intention (i.e., DTOs terminating their activities due to the unsustainability of the intervention’s short-term consequences) culminating in dismantlement. However, surviving DTOs always displayed a high level of resilience, with effective strategies in place to react to threatening events and to continue drug trafficking and dealing.
Pedestrian model
Gudrun Wallentin Dana Kaziyeva Martin Loidl Petra Stutz | Published Monday, August 07, 2023The model generates disaggregated traffic flows of pedestrians, simulating their daily mobility behaviour represented as probabilistic rules. Various parameters of physical infrastructure and travel behaviour can be altered and tested. This allows predicting potential shifts in traffic dynamics in a simulated setting. Moreover, assumptions in decision-making processes are general for mid-sized cities and can be applied to similar areas.
Together with the model files, there is the ODD protocol with the detailed description of model’s structure. Check the associated publication for results and evaluation of the model.
Installation
Download GAMA-platform (GAMA1.8.2 with JDK version) from https://gama-platform.github.io/. The platform requires a minimum of 4 GB of RAM.
…

Seascapes of the Unreal: Using Agent Based Modeling to Examine Traditional Coast Salish Maritime Mobility
Adam Rorabaugh | Published Friday, December 22, 2023Non-traditional tools and mediums can provide unique methodological and interpretive opportunities for archaeologists. In this case, the Unreal Engine (UE), which is typically used for games and media, has provided a powerful tool for non-programmers to engage with 3D visualization and programming as never before. UE has a low cost of entry for researchers as it is free to download and has user-friendly “blueprint” tools that are visual and easily extendable. Traditional maritime mobility in the Salish Sea is examined using an agent-based model developed in blueprints. Focusing on the sea canoe travel of the Straits Salish northwestern Washington State and southwest British Columbia. This simulation integrates GIS data to assess travel time between Coast Salish archaeological village locations and archaeologically represented resource gathering areas. Transportation speeds informed by ethnographic data were used to examine travel times for short forays and longer inter-village journeys. The results found that short forays tended to half day to full day trips when accounting for resource gathering activities. Similarly, many locations in the Salish Sea were accessible in long journeys within two to three days, assuming fair travel conditions. While overall transportation costs to reach sites may be low, models such as these highlight the variability in transport risk and cost. The integration of these types of tools, traditionally used for entertainment, can increase the accessibility of modeling approaches to researchers, be expanded to digital storytelling, including aiding in the teaching of traditional ecological knowledge and placenames, and can have wide applications beyond maritime archaeology.
This is v0.01 of a UE5.2.1 agent based model.
The Pampas Model: An agent-based model of agricultural systems in the Argentinean Pampas
Michael North Federico Bert Guillermo P Podestá Santiago L Rovere Charles Macal | Published Tuesday, July 16, 2013 | Last modified Tuesday, February 17, 2015The Pampas Model is an Agent-Based Model intended to explore the dynamics of structural and land use changes in agricultural systems of the Argentine Pampas in response to climatic, technological economic, and political drivers.
PR-M: The Peer Review Model
Mario Paolucci Francisco Grimaldo | Published Sunday, November 10, 2013 | Last modified Wednesday, July 01, 2015This is an agent-based model of peer review built on the following three entities: papers, scientists and conferences. The model has been implemented on a BDI platform (Jason) that allows to perform both parameter and mechanism exploration.
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.
COOPER - Flood impacts over Cooperative Winemaking Systems
David Nortes Martinez David Nortes-Martinez | Published Thursday, February 08, 2018 | Last modified Friday, March 22, 2019The model simulates flood damages and its propagation through a cooperative, productive, farming system, characterized as a star-type network, where all elements in the system are connected one to each other through a central element.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
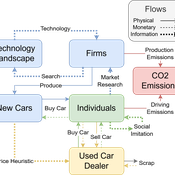
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
Displaying 10 of 217 results for "Andreas Flache" clear search