Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 531 results for "Jingjing Cai" clear search
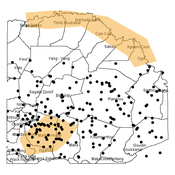
Agent-based modeling of the spatio-temporal distribution of Sahelian transhumant herds
Cheick Amed Diloma Gabriel TRAORE Etienne DELAY Alassane Bah Djibril Diop | Published Tuesday, May 20, 2025Sahelian transhumance is a seasonal pastoral mobility between the transhumant’s terroir of origin and one or more host terroirs. Sahelian transhumance can last several months and extend over hundreds of kilometers. Its purpose is to ensure efficient and inexpensive feeding of the herd’s ruminants. This paper describes an agent-based model to determine the spatio-temporal distribution of Sahelian transhumant herds and their impact on vegetation. Three scenarios based on different values of rainfall and the proportion of vegetation that can be grazed by transhumant herds are simulated. The results of the simulations show that the impact of Sahelian transhumant herds on vegetation is not significant and that rainfall does not impact the alley phase of transhumance. The beginning of the rainy season has a strong temporal impact on the spatial distribution of transhumant herds during the return phase of transhumance.
Diffusion dynamics in small-world networks with heterogeneous consumers
Sebastiano Delre | Published Saturday, September 10, 2011 | Last modified Saturday, April 27, 2013This model simulates diffusion curves and it allows to test how social influence, network structure and consumer heterogeneity affect their spreads and their speeds.

Peer reviewed FishCensus
Miguel Pais | Published Tuesday, December 06, 2016 | Last modified Thursday, February 09, 2017The FishCensus model simulates underwater visual census methods, where a diver estimates the abundance of fish. A separate model is used to shape species behaviours and save them to a file that can be shared and used by the counting model.
Expectation-Based Bayesian Belief Revision
C Merdes Momme Von Sydow Ulrike Hahn | Published Monday, June 19, 2017 | Last modified Monday, August 06, 2018This model implements a Bayesian belief revision model that contrasts an ideal agent in possesion of true likelihoods, an agent using a fixed estimate of trusting its source of information, and an agent updating its trust estimate.
RiskNetABM
Birgit Müller Jürgen Groeneveld Karin Frank Meike Will Friederike Lenel | Published Monday, July 20, 2020 | Last modified Monday, May 03, 2021The fight against poverty is an urgent global challenge. Microinsurance is promoted as a valuable instrument for buffering income losses due to health or climate-related risks of low-income households in developing countries. However, apart from direct positive effects they can have unintended side effects when insured households lower their contribution to traditional arrangements where risk is shared through private monetary support.
RiskNetABM is an agent-based model that captures dynamics between income losses, insurance payments and informal risk-sharing. The model explicitly includes decisions about informal transfers. It can be used to assess the impact of insurance products and informal risk-sharing arrangements on the resilience of smallholders. Specifically, it allows to analyze whether and how economic needs (i.e. level of living costs) and characteristics of extreme events (i.e. frequency, intensity and type of shock) influence the ability of insurance and informal risk-sharing to buffer income shocks. Two types of behavior with regard to private monetary transfers are explicitly distinguished: (1) all households provide transfers whenever they can afford it and (2) insured households do not show solidarity with their uninsured peers.
The model is stylized and is not used to analyze a particular case study, but represents conditions from several regions with different risk contexts where informal risk-sharing networks between smallholder farmers are prevalent.
…
Sensitivity of a population submitted to floods to unknown upcoming floods and parameters of the dynamics
Sylvie Huet | Published Wednesday, September 22, 2021This work is a java implementation of a study of the viability of a population submitted to floods. The population derives some benefit from living in a certain environment. However, in this environment, floods can occur and cause damage. An individual protection measure can be adopted by those who wish and have the means to do so. The protection measure reduces the damage in case of a flood. However, the effectiveness of this measure deteriorates over time. Individual motivation to adopt this measure is boosted by the occurrence of a flood. Moreover, the public authorities can encourage the population to adopt this measure by carrying out information campaigns, but this comes at a cost. People’s decisions are modelled based on the Protection Motivation Theory (Rogers1975, Rogers 1997, Maddux1983) arguing that the motivation to protect themselves depends on their perception of risk, their capacity to cope with risk and their socio-demographic characteristics.
While the control designing proper informations campaigns to remain viable every time is computed in the work presented in https://www.comses.net/codebases/e5c17b1f-0121-4461-9ae2-919b6fe27cc4/releases/1.0.0/, the aim of the present work is to produce maps of probable viability in case the serie of upcoming floods is unknown as well as much of the parameters for the population dynamics. These maps are bi-dimensional, based on the value of known parameters: the current average wealth of the population and their actual or possible future annual revenues.

Peer reviewed ArchMatNet: Archaeological Material Networks
Claudine Gravel-Miguel Robert Bischoff Cecilia Padilla-Iglesias | Published Monday, February 20, 2023The purpose of the model is to investigate how different factors affect the ability of researchers to reconstruct prehistoric social networks from artifact stylistic similarities, as well as the overall diversity of cultural traits observed in archaeological assemblages. Given that cultural transmission and evolution is affected by multiple interacting phenomena, our model allows to simultaneously explore six sets of factors that may condition how social networks relate to shared culture between individuals and groups:
- Factors relating to the structure of social groups
- Factors relating to the cultural traits in question
- Factors relating to individual learning strategies
- Factors relating to the environment
…
Agent-Based Computational Modeling of Cryptocurrency Design
Felix Ude | Published Friday, June 28, 2019Agent-Based Computational Model of the cryptocurrency Bitcoin with a realistic market and transaction system. Bitcoin’s transaction limit (i.e. block size) and Bitcoin generation can be calibrated and optimized for wealth and network’s hashing power by the Non-Dominated Sorted Genetic Algorithm - II.
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.

Cluster Analysis
Lars Spång | Published Sunday, January 14, 2018This model illustrates how to apply a simple cluster-analysis on points distributed around 5 centers. The result can be displayed in shades of a color or a spectacular colored pattern.
Displaying 10 of 531 results for "Jingjing Cai" clear search