Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 5 of 5 results power law clear search
The Targeted Subsidies Plan Model
Hassan Bashiri | Published Thursday, September 21, 2023The targeted subsidies plan model is based on the economic concept of targeted subsidies.
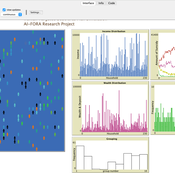
The targeted subsidies plan model simulates the distribution of subsidies among households in a community over several years. The model assumes that the government allocates a fixed amount of money each year for the purpose of distributing cash subsidies to eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount. The model simulates the impact of the subsidy distribution process on the income and property of households in the community over time.
The model simulates a community of 230 households, each with a household income and wealth that follows a power-law distribution. The number of household members is modeled by a normal distribution. The model allocates a fixed amount of money each year for the purpose of distributing cash subsidies among eligible households. The eligible households are identified by dividing families into 10 groups based on their income, property, and wealth. The subsidy is distributed to the first four groups, with the first group receiving the highest subsidy amount.
The model runs for a period of 10 years, with the subsidy distribution process occurring every month. The subsidy received by each household is assumed to be spent, and a small portion may be saved and added to the household’s property. At the end of each year, the grouping of households based on income and assets is redone, and a number of families may be moved from one group to another based on changes in their income and property.
…
Exploring the Effects of Link Recommendations on Social Networks
Andrew Crooks Ciara Sibley | Published Thursday, March 19, 2020The purpose of this model is explore how “friend-of-friend” link recommendations, which are commonly used on social networking sites, impact online social network structure. Specifically, this model generates online social networks, by connecting individuals based upon varying proportions of a) connections from the real world and b) link recommendations. Links formed by recommendation mimic mutual connection, or friend-of-friend algorithms. Generated networks can then be analyzed, by the included scripts, to assess the influence that different proportions of link recommendations have on network properties, specifically: clustering, modularity, path length, eccentricity, diameter, and degree distribution.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
Citation Agents: A model of collective learning through scientific publication
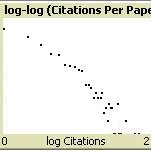
Christopher Watts | Published Friday, July 31, 2015Simulates the construction of scientific journal publications, including authors, references, contents and peer review. Also simulates collective learning on a fitness landscape. Described in: Watts, Christopher & Nigel Gilbert (forthcoming) “Does cumulative advantage affect collective learning in science? An agent-based simulation”, Scientometrics.
Universal Darwinism in Dutch Greenhouses
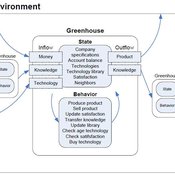
Julia Kasmire | Published Wednesday, May 09, 2012 | Last modified Saturday, April 27, 2013An ABM, derived from a case study and a series of surveys with greenhouse growers in the Westland, Netherlands. Experiments using this model showshow that the greenhouse horticulture industry displays diversity, adaptive complexity and an uneven distribution, which all suggest that the industry is an evolving system.